[CS면접] 백엔드 신입 개발자 필수 대답 질문 (초급)
HTTP Method get, post의 차이점을 설명해 보시오.
| get | post |
| - 클라이언트에서 서버로 리소스를 요청하기 위해 사용하는 method - 서버에서 원하는 리소스를 가져와 조회 할 때 사용한다 - 리소스의 값, 내용, 상태를 바꾸지 않는다 - get은 캐시되어 브라우저에 기록된다 |
- 클라이언트에서 서버로 리소스를 생성/수정할 때 사용하는 method - 서버의 리소스 값, 상태를 수정하기 위해 사용한다 - post는 캐시되지 않아 브라우저에 기록되지 않는다 |
HTTP 상태 코드에 대해 설명해 보시오.
주요 상태 코드 (200, 404, 503)에 대해선 설명할 수 있어야 한다.
- 200 : 성공(OK), 요청이 성공적이다. 요청에 따른 응답을 반환한다.
- 404 : 요청받은 리소스를 찾을 수 없을 때 사용한다. 브라우저에선 알려지지 않은 URL을 의미한다.
- 서버는 인증받지 않은 클라이언트에게 리소스를 숨기기 위해 이 응답을 403 대신에 전송하는 경우도 있다
- 503 : 서버가 요청을 처리할 준비가 되지 않은 상태. 유지 보수를 위해 서버가 중단되었거나 과부하가 걸린 상태일 경우 발생한다.
그 외, 1번대 부터 5번대 까지 대략적으로 의미를 설명할 수 있어야 한다.
- 1xx (정보) : 요청을 받았으며 프로세스를 진행한다
- 2xx (성공) : 요청을 성공적으로 받았고 수용한다
- 3xx (리다이렉션) : 요청 완료를 위해 추가 작업 필요
- 4xx (클라이언트 오류) : 요청 문법 오류 or 요청 처리 불가
- 5xx (서버 오류) : 서버가 유효한 요청을 처리할 수 없는 상태
프로세스와 스레드의 차이에 대해 설명해 보시오.
| 프로세스 | 스레드 |
| - 자원을 할당받는 작업의 단위 - 프로세스는 자원 공유를 하지 않는다 |
- 스레드는 프로세스가 할당받은 자원을 이용하는 실행 단위 - 스레드끼리 자원 공유를 한다 |
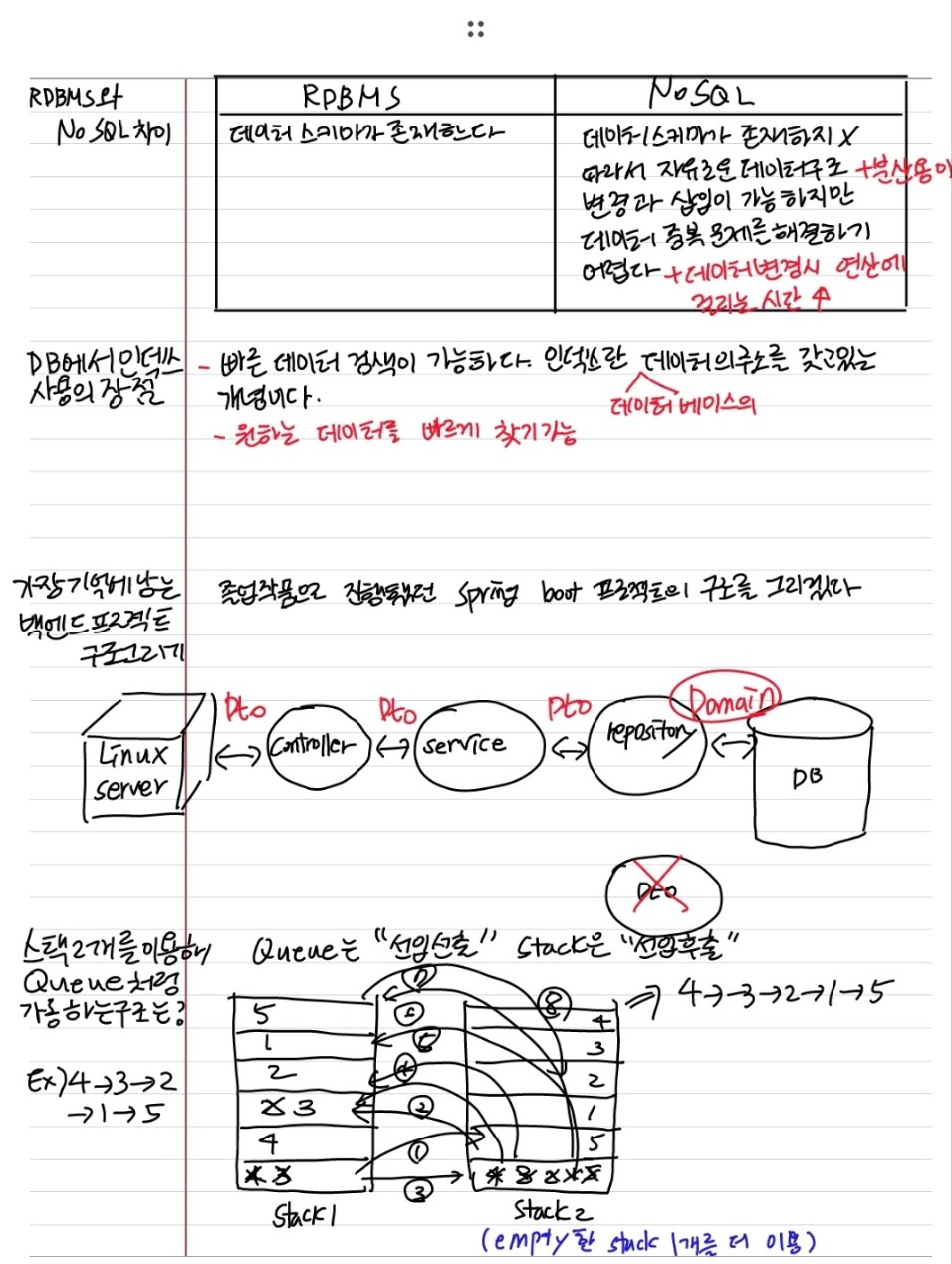
RDB와 NoSQL의 차이에 대해 설명해 보시오.
| RDBMS | NoSQL |
| - 데이터 스키마가 존재 | - 데이터 스키마가 존재하지 않는다 - 데이터 스키마가 존재하지 않아 데이터 구조 변화가 자유롭고 데이터 분산이 용이하다 - 단, 데이터 중복이 발생할 수 있고 데이터 수정 연산 수행 시간이 오래 걸린다 |
DB에서 인덱스를 사용했을 때 어떤 장점이 있는지 설명해 보시오.
데이터 검색 성능에 큰 영향을 끼치는 요인이 인덱스이다.
대용량 DB에서 빠르게 필요한 데이터를 찾기 위해 필요한 것이 인덱스이다.
인덱스란 DB에서 데이터의 주소를 갖고있는 것이며 원하는 데이터를 빠르게 찾을 수 있다는 장점이 있다
만약, 적절한 인덱스를 찾지 못하는 경우 DB 전체 조회가 필요해서 데이터 조회가 굉장히 오래 걸리게 된다.
GC 가비지 컬렉션에 대해 설명해 보시오.
가비지 컬렉션이란 프로그래머가 동적으로 할당한 메모리 영역 중 더이상 쓰이지 않는 가비지 영역을 찾아서 해제하는 기능이다.
자바의 메모리는 Young, Old, Perm 세 영역으로 나뉘는데 이중 Perm 영역은 Class, Method 등 코드가 저장되는 영역으로 JVM에 의해 사용된다. Young영역(New)은 생성된지 얼마 되지 않은 객체들을 저장하는 장소, Old 영역은 Young 영역에서 오래된 객체가 이동되어 저장되는 영역이다.
만약 Old 영역이 가득찼을 때 Full GC가 발생하게 되는데 이때 애플리케이션에 부하가 발생하여 Full GC 발생 순간에 성능이 저하하게 된다. 따라서 자바 이슈를 유발하게 되는 Full GC의 이론을 이해해야 한다.
가장 기억에 남는 백엔드 프로젝트 구조를 설명해 보시오.
아래 사진 첨부
병렬 프로그래밍에 대해 설명해 보시오. 어떤 부분을 유의해야 하는지 설명해 보시오.
병렬 프로그래밍이란 큰 문제를 나누어 동시에 해결하도록 하는 방법이다. 자바에선 멀티 프로세싱 / 멀티 쓰레딩을 구현하여 병렬 프로그래밍을 구현할 수 있다.
프로세스 or 스레드가 문제를 나누어 동시에 처리하기 때문에 처리 속도가 향상되지만 구현 난이도가 올라가 유지보수가 어려워질 수 있다.
유의할 점은 공유된 자원에 여러 개의 프로세스/스레드가 접근하면 Critical Section 문제가 발생할 수 있다.
이를 해결하기 위해 데이터를 한 번에 하나의 프로세스만 접근할 수 있도록 제한을 두는 동기화 방식을 취해야 한다.
보통 동기화 방식으론 뮤텍스(Mutex)와 세마포어(Semaphore)가 있다.
단, 이 두 방식 모두 완벽한 기법이 아니므로 교착 상태가 발생할 수 있다는 문제점이 있으며 데이터 무결성을 보장할 수 없다. 하지만 상호배제를 위한 기본적인 문법이므로 더 복잡한 매커니즘을 적용해 개선된 성능을 가질 수 있도록 해야 한다.
| Mutex (뮤텍스) | Semaphore (세마포어) |
| - 한 스레드/프로세스에 의해 소유될 수 있는 Key를 기반 - Key에 해당하는 어떤 객체가 있으며 이 객체를 소유한 스레드/프로세스만이 공유자원에 접근할 수 있다. - 동기화, 락을 사용함으로써 뮤텍스 객체를 두 스레드가 동시에 사용할 수 없다. - 동기화 대상이 오직 1개일 때 사용 - 자원 소유 가능, 책임을 갖는다 - 상태가 0, 1 둘 뿐이므로 Lock을 가질 수 있고 소유하고 있는 스레드만이 이 Mutex를 해제 할 수 있다 - 프로세스 범위 => 프로세스가 종료될 때 자동으로 Clean up |
- 현재 공유자원에 접근할 수 있는 스레드/프로세스의 수를 나타내는 값을 기반 - 공유된 자원의 데이터/임계영역등에 여러 스레드/프로세스가 접근하는 것을 막는다 - 공유 자원에 접근할 수 있는 프로세스의 최대 허용치만큼만 동시에 사용자가 접근할 수 있으며 각 프로세스는 세마포어의 값을 확인/변경할 수 있다 - 동기화 대상이 1개 이상일 때 사용 - 자원 소유가 불가 - 세마포어를 소유하지 않는 스레드가 세마포어를 해제할 수 있다 - 시스템 범위 => 파일 시스템 상의 파일로 존재 |
LRU 캐시에 대해 설명해 보시오.
LRU 캐시란 Least Recently Used Cache 를 뜻한다.
캐시 메모리가 다 찼을 때, 가장 오랫동안 사용되지 않았던 캐시를 메모리에서 삭제하는 알고리즘이다.
캐시를 교체하는 알고리즘 = 페이지 교체 알고리즘
- FIFO (First In First Out) : 적재된 시간을 기준
- LFU (Least Frequently Used) : 가장 적은 횟수를 참조
- LRU (Least Recently Used) : 가장 오랫동안 참조되지 않은 페이지를 교체
CI/CD란?
CI/CD란 Continuous Integration/Continuous Delivery의 약자로 애플리케이션 개발 단계를 자동화하여 애플리케이션을 더욱 짧은 주기로 고객에게 제공하는 방법이다.
기본 개념은 지속적인 통합, 지속적인 서비스 제공, 지속적인 배포이다.
즉, 서비스 빌드부터 배포까지의 과정을 자동화하는 과정이다.
예를 들어, github에 코드 커밋을 통해 코드 변경 사항이 생기고 이를 push하고 코드에 변경사항이 생겼을 때 변경 사항을 감지하여 jenkins와 같은 tool을 이용해 자동으로 빌드하도록 설계 해볼 수 있겠다.
마이크로 서비스와 모놀리틱 서비스의 차이점을 설명해 보시오. => ?
| 마이크로 아키텍처 (MSA) | 모놀리식 아키텍처 (MA) |
| - MA의 단점인 서비스가 커지면 시스템이 무거워 지는 점을 해결하기 위함 - 여러 모듈을 조합하여 애플리케이션을 구현하는 방식 - 모듈마다 자체 DB를 가지고 있기에 개발부터 배포까지 효율적으로 수행 가능 - 단, 독립적이고 확장성을 고려한 설계가 어려운 점 + 모듈이 나뉘어져 있어 트랜잭션 처리가 어려운 점이 단점이다 - 여러 비즈니스 로직은 각자의 DB 환경을 공유하고 모듈별로 애플리케이션과 독립적으로 통신 - 각 기능들이 독립적인 시스템으로 구성되어 있어 이해하기 쉽고 유지보수가 쉽다 - 하나의 서비스에 발생한 문제는 해하나의 서비스만 수정 후 빌드&배포하므로 빌드, 배포 시간이 감소한다 - 각 기능에 맞는 언어, 프레임워크를 선택할 수 있다 - 통합테스트가 어렵다 - 서비스 확장 가능성이 높거나 시스템이 크다면 선택 |
- 하나의 아키텍처를 두는 방식 - 개발과 관리가 용이하다 - 단, 시스템이 복잡해질수록 코드 이해가 어렵고 유지보수가 어려워 진다는 단점이 있다 - 또한, 작은 버그를 수정해도 전체를 재빌드&배포 해야한다는 단점이 있어 시스이 무거워 진다 - 여러 비즈니스 로직을 담은 시스템이 하나의 DB와 하나의 애플리케이션과 상호작용 - 하나의 시스템으로 테스트하기에 통합 테스트가 쉽다 - 서비스 확장 가능성이 낮고 시스템이 작다면 선택 |

Reference
- https://velog.io/@heoseungyeon/MSA-vs-%EB%AA%A8%EB%86%80%EB%A6%AC%EC%8B%9D-akg64flw
- https://j2wooooo.tistory.com/121
- https://hbase.tistory.com/308
- https://heeonii.tistory.com/14