[리뷰레인저] 확장성을 해치는 swtich 분기문을 없애자 - 1
해당 게시글은 프로젝트 '리뷰레인저'에 대해 개인 리팩토링 과정을 정리한 시리즈 글입니다.
이번 게시글의 주제는 'swtich문에 의한 로직의 유지보수성, 확장성이 저하되는 현상에 대한 개선안'입니다.
기존 로직의 문제점들

서비스 로직은 이름과 내부를 봤을 때 어떤 기능을 수행하는지 딱 알 수 있어야 한다
위 사진이 내부와 이름으로 어떤 기능을 수행하는지 바로 알 수 있는 예시이다
`getAllFinalReveiwResults` 메소드는 모든 최종 리뷰 결과를 가져오는 메소드 이름 + 유저id와 상태로 모든 최종 리뷰를 가져오는 기능임이 한번에 보인다.
1) 최종 리뷰를 생성하고 조회하는 로직은 어떤 기능을 수행하는지 알기 힘든 문제
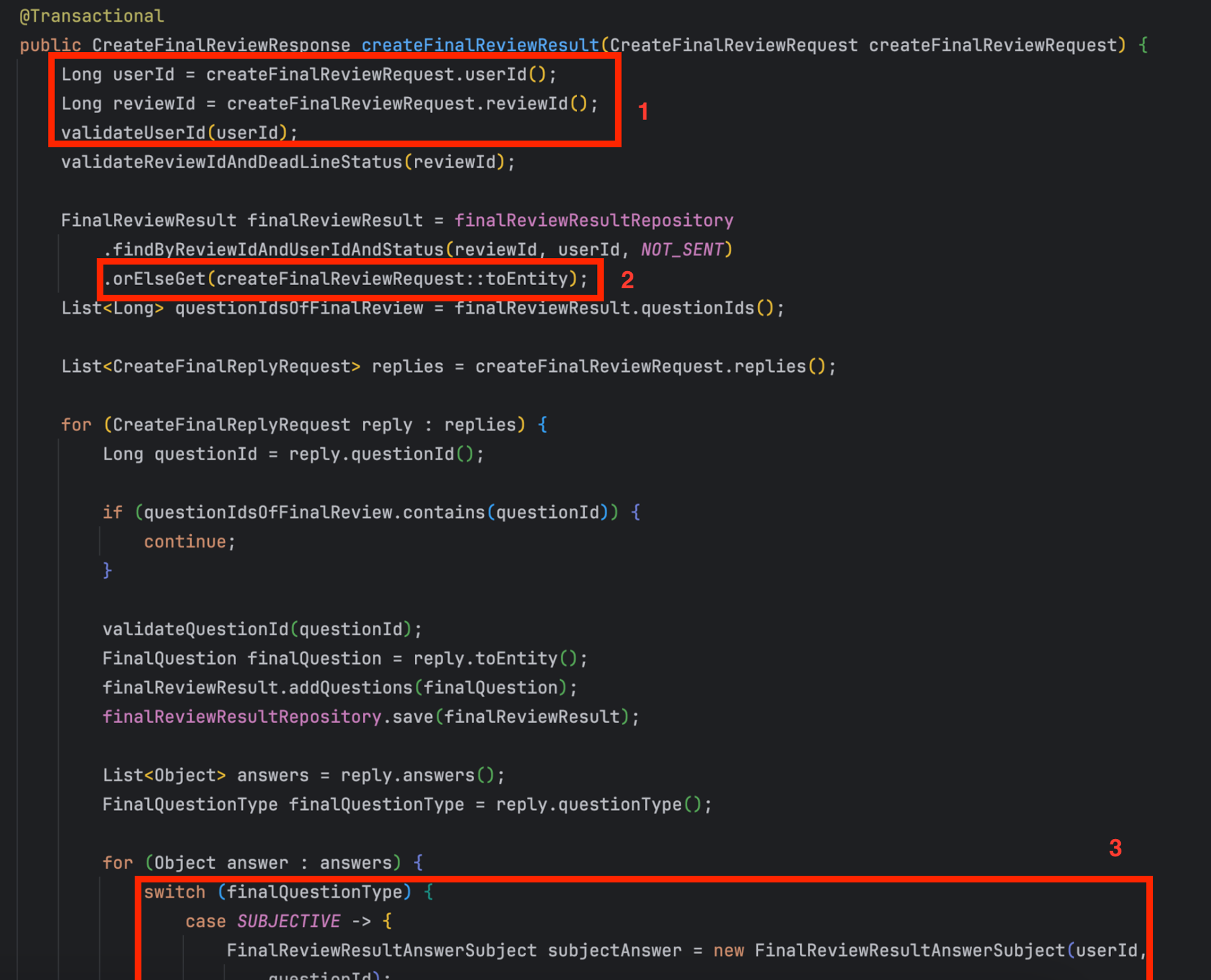
위의 사진이 최종 리뷰를 생성하는 로직이다.
하지만 create라는 이름은 너무 모호하기도 하면서 전체적인 로직이 너무 많아 최종 리뷰를 생성한다고 이해하기가 어렵다는 단점이 있다
이름도 바꾸되 해당 메소드에서 이루어지고 있는 너무 많은 로직을 메소드 분리를 통해 가독성을 높일 필요가 있다.
객체지향 체조 원칙에 따라 하나의 메소드는 하나의 역할만 할 수 있어야 한다
2) userId에 대한 검증이 유의미하지 않다
위 이미지의 1번 상자를 보면 userId에 대한 검증을 시도하고 있다
하지만, 이와 같은 검증이 유의미한지 생각해보자
userId는 서버에서 클라이언트에게 넘겨주는 값이다 그렇기 때문에 클라이언트가 데이터를 변경해서 보낼 가능성은 없다고 보면 된다
또한, userId가 일치하지 않아 예외가 발생해도 예외 처리로 해줄 수 있는 것이 없다
즉, 유의미하지 않은 userId 검증인 것이다 (+다른 곳도 userId에 대한 검증이 있던가 해야하는데 일관성이 없다)
결론은 무조건적인 검증이 좋은 것은 아니란 것이다
3) 객체지향 체조 원칙에 위배되는 orElseGet을 사용한다
그렇다면 2번 상자를 보자. `orElseGet`을 사용하고 있다.
객체지향 체조 원칙 9가지(https://bestsu.tistory.com/108)를 보면 2번에 else를 사용하지 않는다는 구문이 있다
이는 `if-else`를 사용하는 것과 같은 효과를 보인다. 즉, 가독성이 떨어지는 문제가 발생한다
4) 설문 결과 타입을 Object로 받아와 타입에 대한 검증이 불가능하다
가장 큰 문제는 `Object` 타입을 통해 설문 결과를 받아오고 있는데 이는 서버에서 문제가 될 수 있다
왜냐하면, 모든 타입에 대해서 들어오기 때문에 특정 타입에 대한 검증이 불가능하기 때문이다 (허걱)
그렇기 때문에 `Object` 타입으로 입력값을 받는것은 지양하도록 하자
5) 최종 리뷰 생성 및 조회에 대한 switch문으로 코드의 확장성과 유연성이 떨어진다 ⭐
다음 문제론 분기문(case)에 대한 문제이다. 개선안이 2가지가 있다
첫번째 개선안은 Object 타입에 따른 finalQuestionType을 분기 처리하는 것이 아니라 finalQuestionType을 먼저 확인하고 이후 answers를 처리하는 것이다
왜냐하면 현재 위 코드 같은 경우 요청값을 생각해보면 finalQuestionType이 같은 상태로 answer이 여러개 들어오는 것이다
그렇기 때문에 finalQuestionType만 처음 구분해서 이후엔 같은 타입의 answers를 계속 넣어주면 되는데 현재의 코드는 불필요한 finalQuestionType 분류가 이루어지고 있다
두번째 개선안은 interface를 통해 Object 타입을 제거하고 finalQuestionType에 대한 분기를 없애는 것이다 ⭐
‘추상화’를 통해 구현체에 따라 save가 실행되도록 변경한다면 case 분기문이 사라질 수 있다
아래 사진은 switch문으로 인한 코드의 확장성과 유연성이 떨어지는 모습을 보여주고 있다.
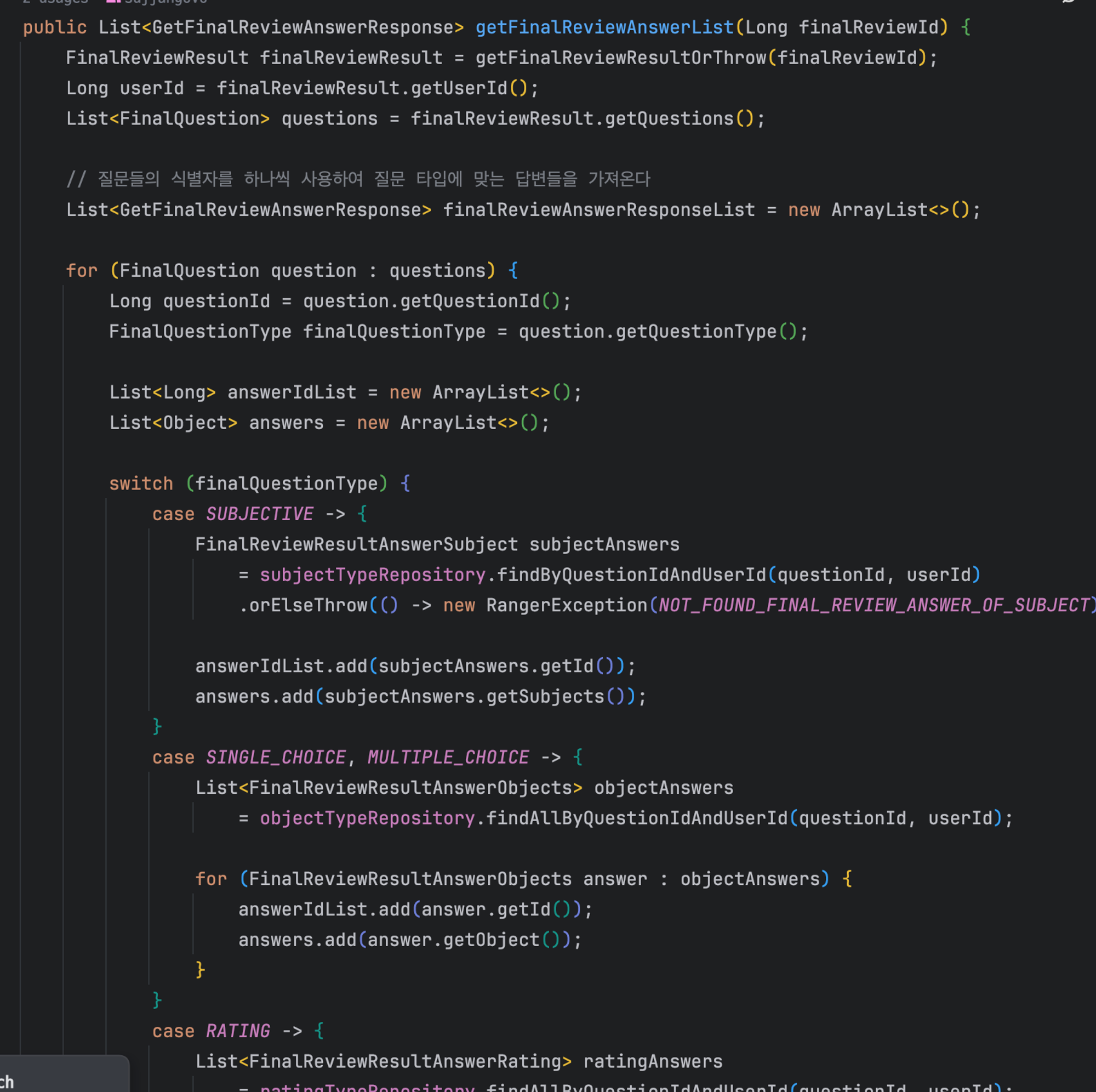
+ 최종 리뷰를 조회하는 로직도 마찬가지이다
finalQuestionType에 대한 분기문을 interface를 통한 ‘추상화’를 통해 해결할 수 있다
이러한 분기문이 문제가 되는 이유는 `확장성`때문이다. 만약, 질문 타입이 추가가 된다면 어떨거 같은가?
최종 리뷰 생성과 조회 둘 다 코드가 변하게 되는 불상사가 일어나게 된다. swtich문에 타입을 계속 추가..해야함
또한, 운영자가 타입을 추가해달라고 했을 때 우선순위가 낮아져 사용자에게 다양한 기능을 제공해줄 수 있는 텀이 길어지게 되는 것이다.
그 외)
하지만, 근본적으로 설계단의 문제로 2중 for문을 제거하기란 어려웠다.
이러한 일을 계기로 개발을 시작하기 전 도메인 설계의 중요성을 더욱 깨닫게 되었다
설게에 따라서 같은 로직이 굉장히 유연해질수도 있고 유지보수가 어려워질 수도 있음을 정말 깨달았다
특히 최종 리뷰를 생성하는 설계에 조금 더 신경을 썻다면 사용자가 마감 버튼을 누르는 동시에 최종 리뷰가 생성되게 할 수 있었다
최종 리뷰를 생성할 때 요청 JSON값을 서버에 좀 더 친화적으로 작성했다면 클라이언트와 서버 둘 다 유연해질 수 있었다
또한, 마감 다음 전송 버튼을 누를 때 최종 리뷰가 생성된다면 데이터가 많을 경우 전송이 늦어져 사용자가 최종 리뷰를 늦게 받게되는 상황이 생길 수도 있다
이렇게 많은 점들을 설계단에서 놓친 것 같아 아쉽지만 다음 프로젝트에 밑거름이 될 것 이다
해결 방안
위의 문제점들을 기반으로 최종 리뷰 결과 생성 및 조회 로직을 아래의 리스트를 중점으로 수정하고자 한다
- create같이 애매한 이름은 save로 바꾸어 의미전달을 좀 더 확실하게 하자
- `Object` 타입과 같이 모든 타입이 들어와 검증이 불가능하게 되는 점을 수정한다
- 기능 확장을 고려하여 case문을 제거하고 추상화를 통해 로직이 실행될 수 있도록 한다 (유연성)
- `orElseGet` 과 같은 가독성이 떨어지는 구문을 수정하자
- 너무 많은 기능을 가진 crate 메소드를 메소드 분리를 통해 가독성을 높이자
수정 후 로직
1️⃣ create같이 애매한 이름은 save로 바꾸어 의미전달을 좀 더 확실하게 한다
생성한다는 느낌보다는 최종 리뷰 결과를 db에 ‘저장’한다는 느낌이 더 강하도록 save로 메소드 이름을 바꾸었다
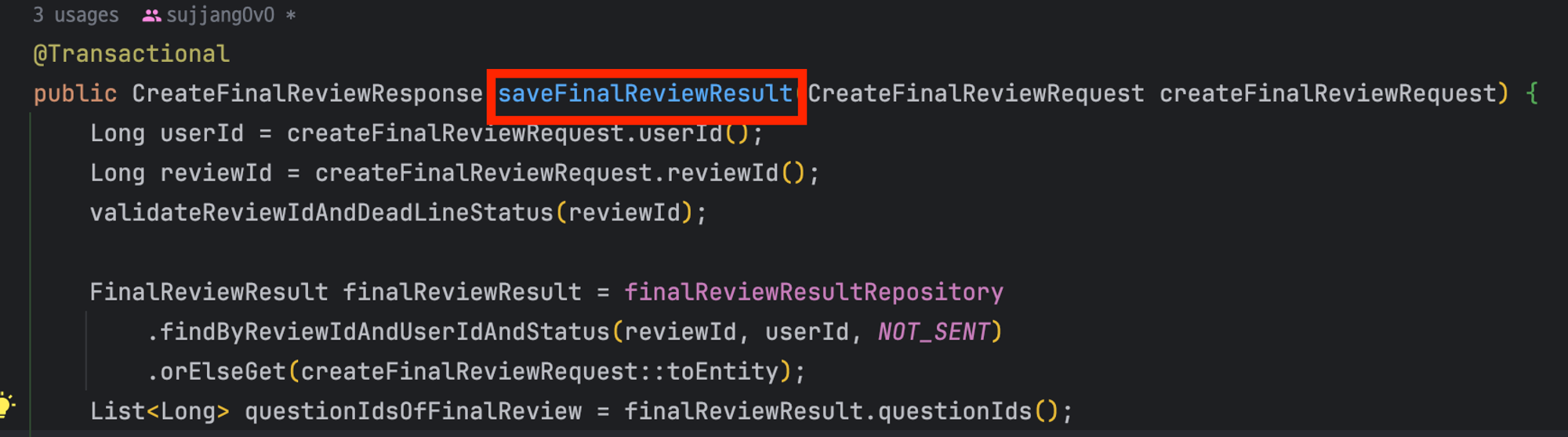
생성한다는 느낌보다는 최종 리뷰 결과를 db에 ‘저장’한다는 느낌이 더 강하도록 save로 메소드 이름을 바꾸어 주었다!
2️⃣ Object 타입과 같이 모든 타입이 들어와 검증이 어려운 점을 수정하자
먼저 데이터에 사용되는 형식을 정리해보자
- 주관식 데이터 형식 - String
- 객관식 데이터 형식 - String
- 별점 데이터 형식 - Double
- 드롭다운 데이터 형식 - String
- 육각스탯 데이터 형식 - String + Double
정리하자면 String, Double, (String+Double)로 총 3가지 타입이 필요하다
이를 포괄적으로 가지는 인터페이스로 생성하고 위 3가지 타입의 Class를 구현체로 만들어주자
아래부턴 코드로 확인하도록 하자

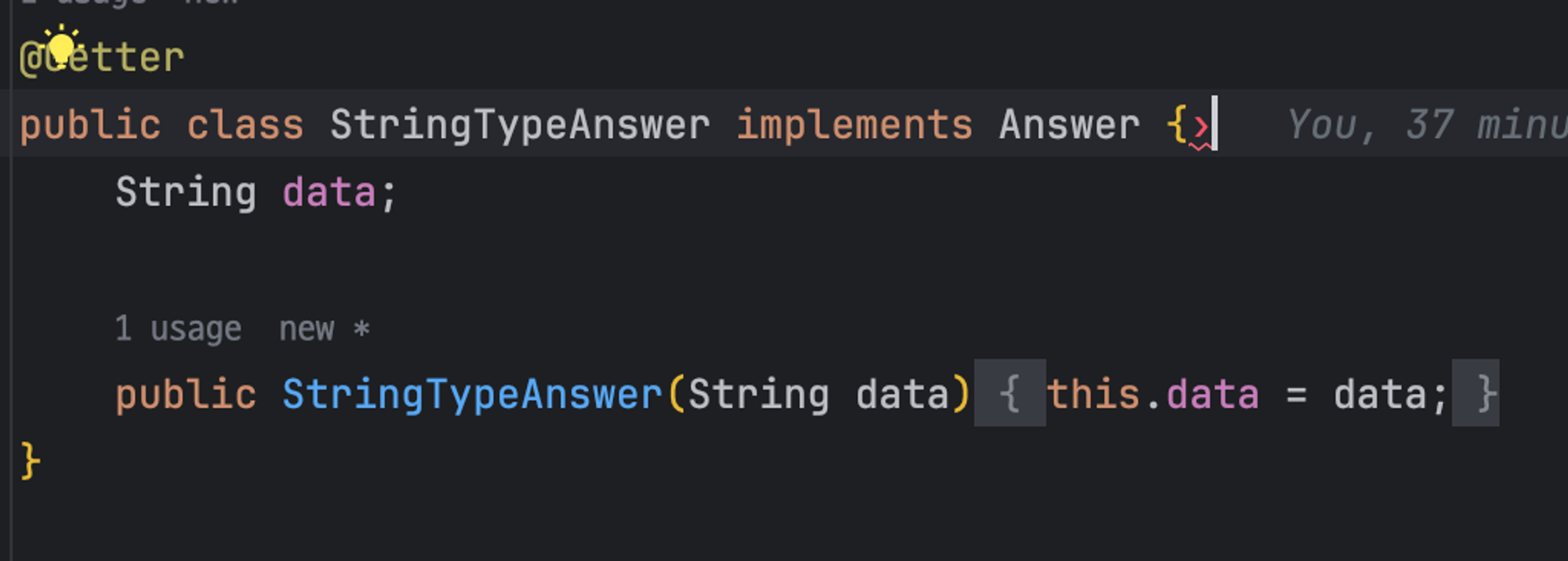
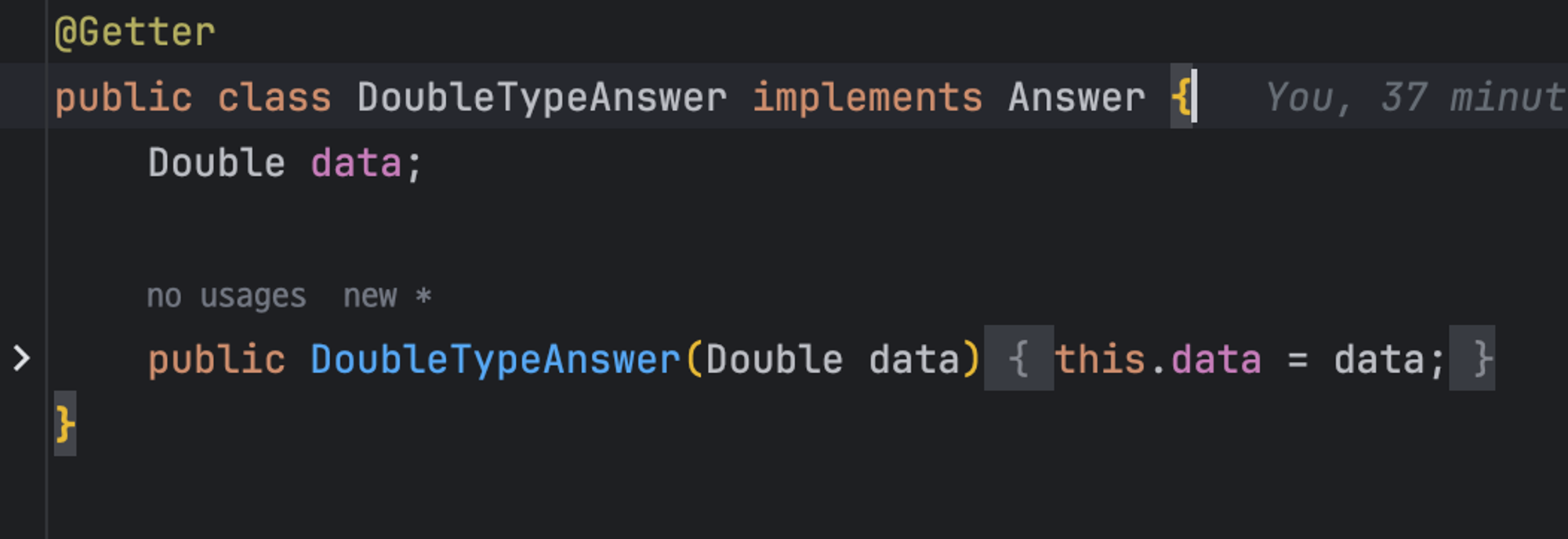
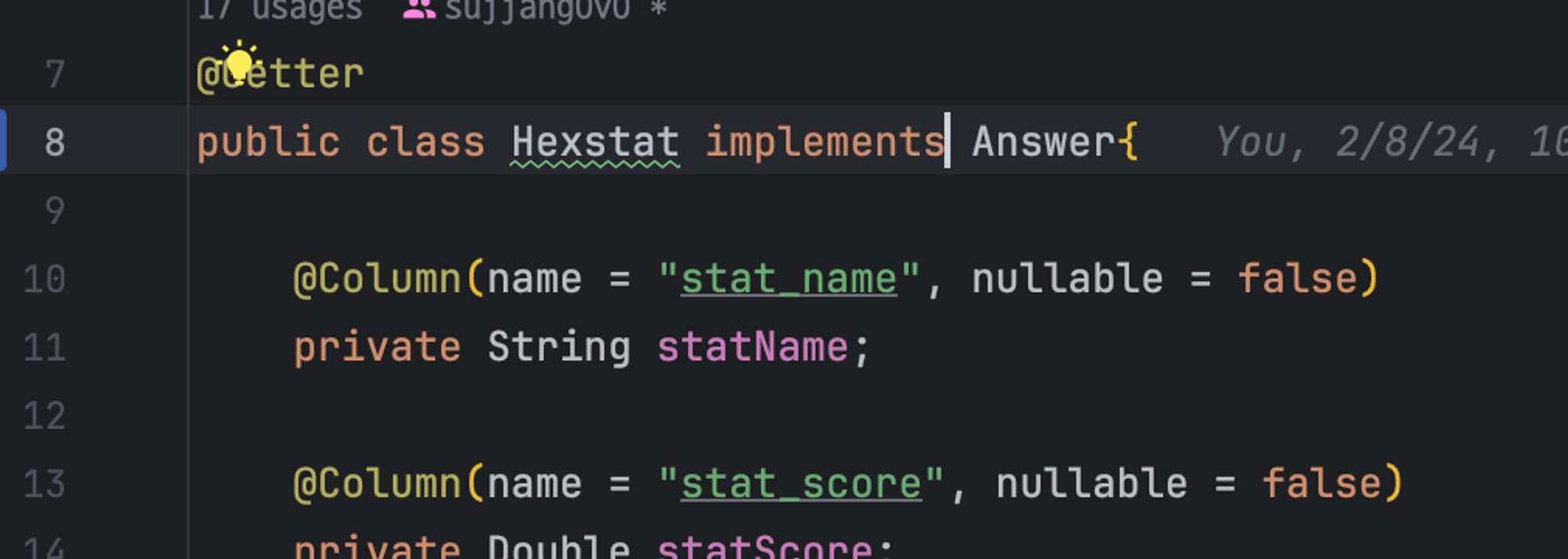
`StrintTypeAnswer`, `DoubleTypeAnswer`, `Hexstat`는 Answer을 구현하고 있다.
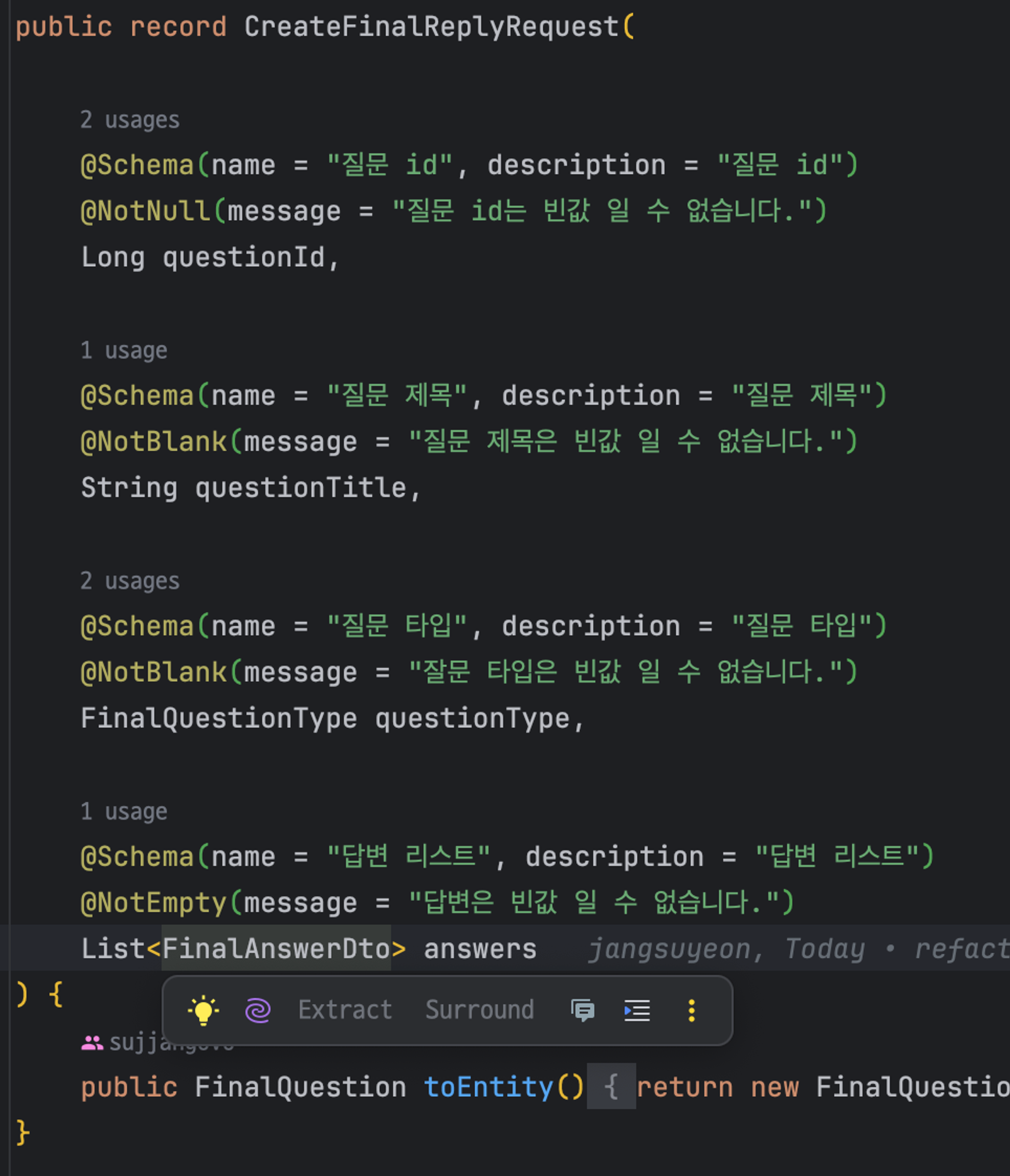
요청 DTO에 있던 Object타입의 List도 Answer `DTO`타입의 List 로 변경해 주었다
(마찬가지로 Answer도 도메인으로 외부에 노출되면 안 되기 때문이다)
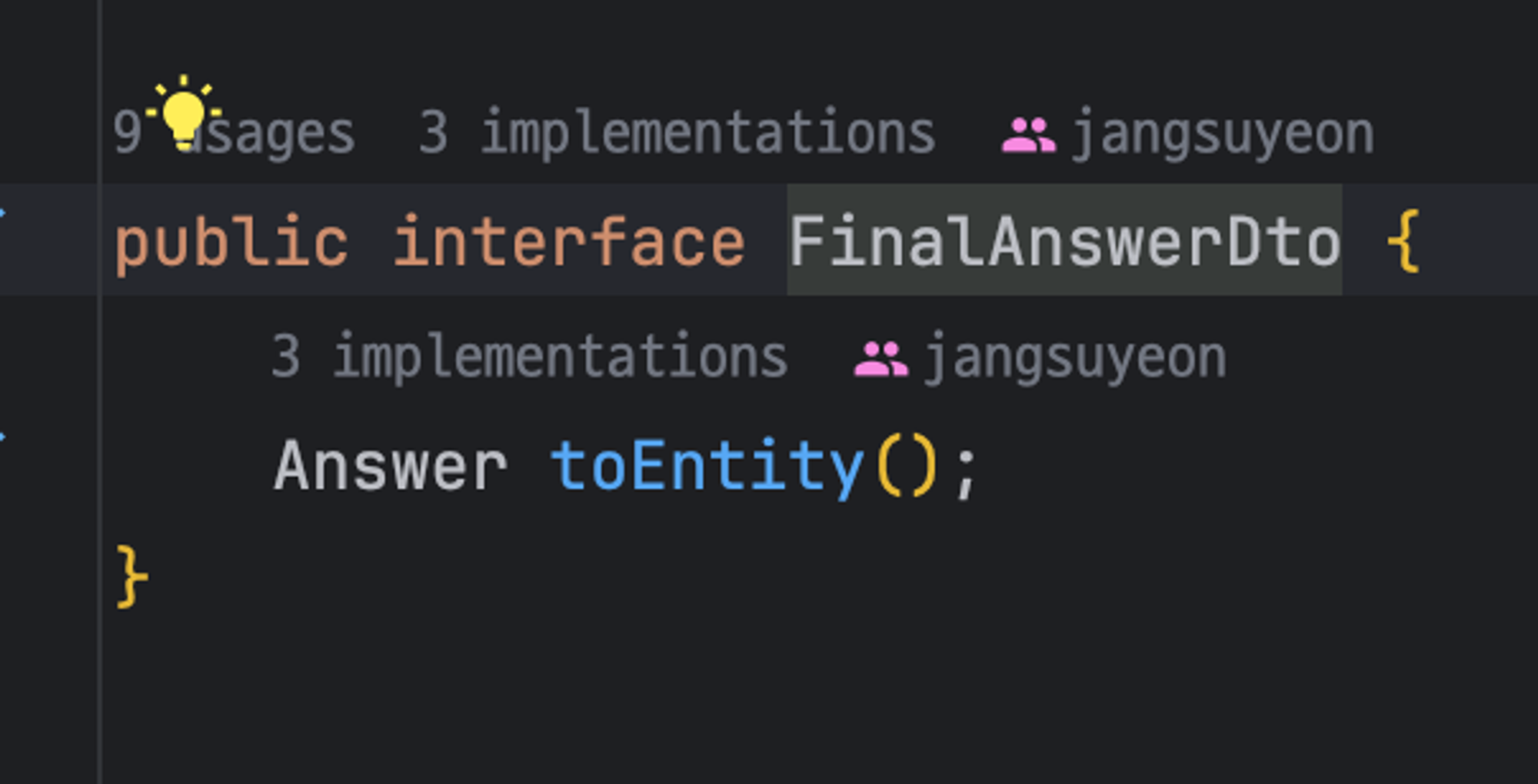
Entity로의 전환은 로직상 모든 FinalAnswerDto가 필요하기 때문에 구현을 강제화 했다
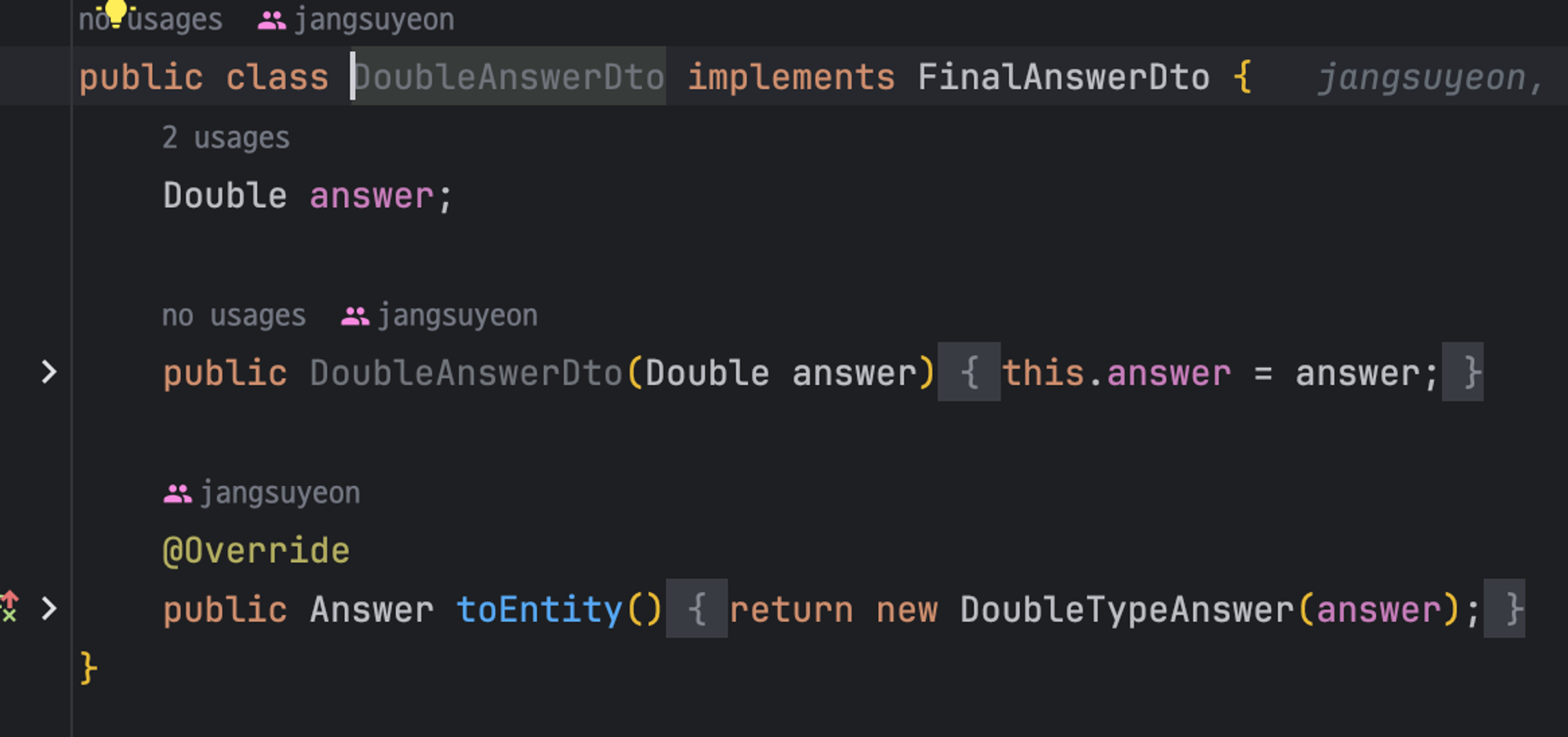
이 외에도 `StringAnswerDto`, `StringAnswerDto`를 구현해주었다
결과⭐ >
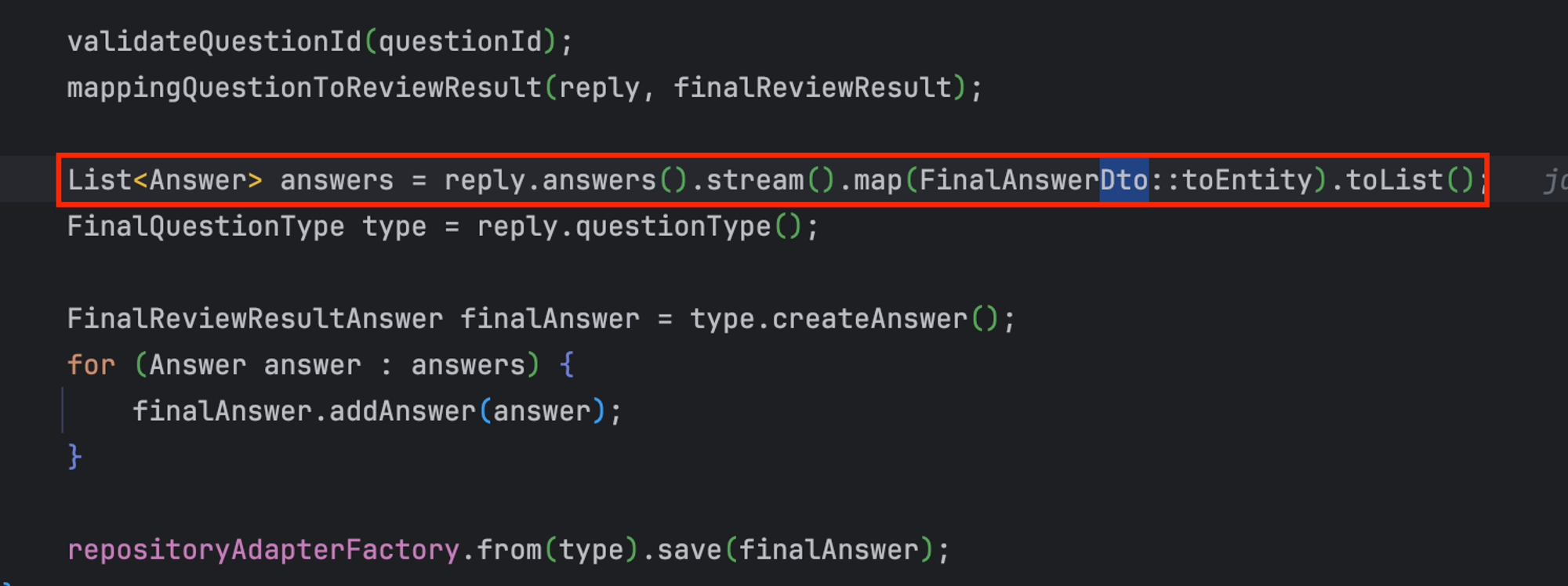
이렇게되면 모든 타입(Object는 모든 타입의 부모)이 입력으로 들어오는 것을 막고 Answer DTO의 구현체만 들어올 수 있게 되어 데이터 검증이 훨씬 유연해진다
참고로 요청 DTO를 변경했기 때문에 클라이언트와의 충분한 상의가 필요한 부분이다.
각 타입마다 DTO가 다르기 때문에 이 점 유의해야 한다.
추가로 가장 좋은 점은 클라이언트의 요청으로부터 데이터를 받아오는 것이 아니라 서버 자체로부터 해결하는 것이다
따라서, 추후에는 더 고도화 된 리팩토링을 진행할 때는 클라이언트에 의존하지 않고 서버로 부터 데이터를 받아와 해결하도록 하자.
3️⃣ 기능 확장을 고려하여 case문을 제거하고 추상화를 통해 로직이 구현될 수 있도록 하자
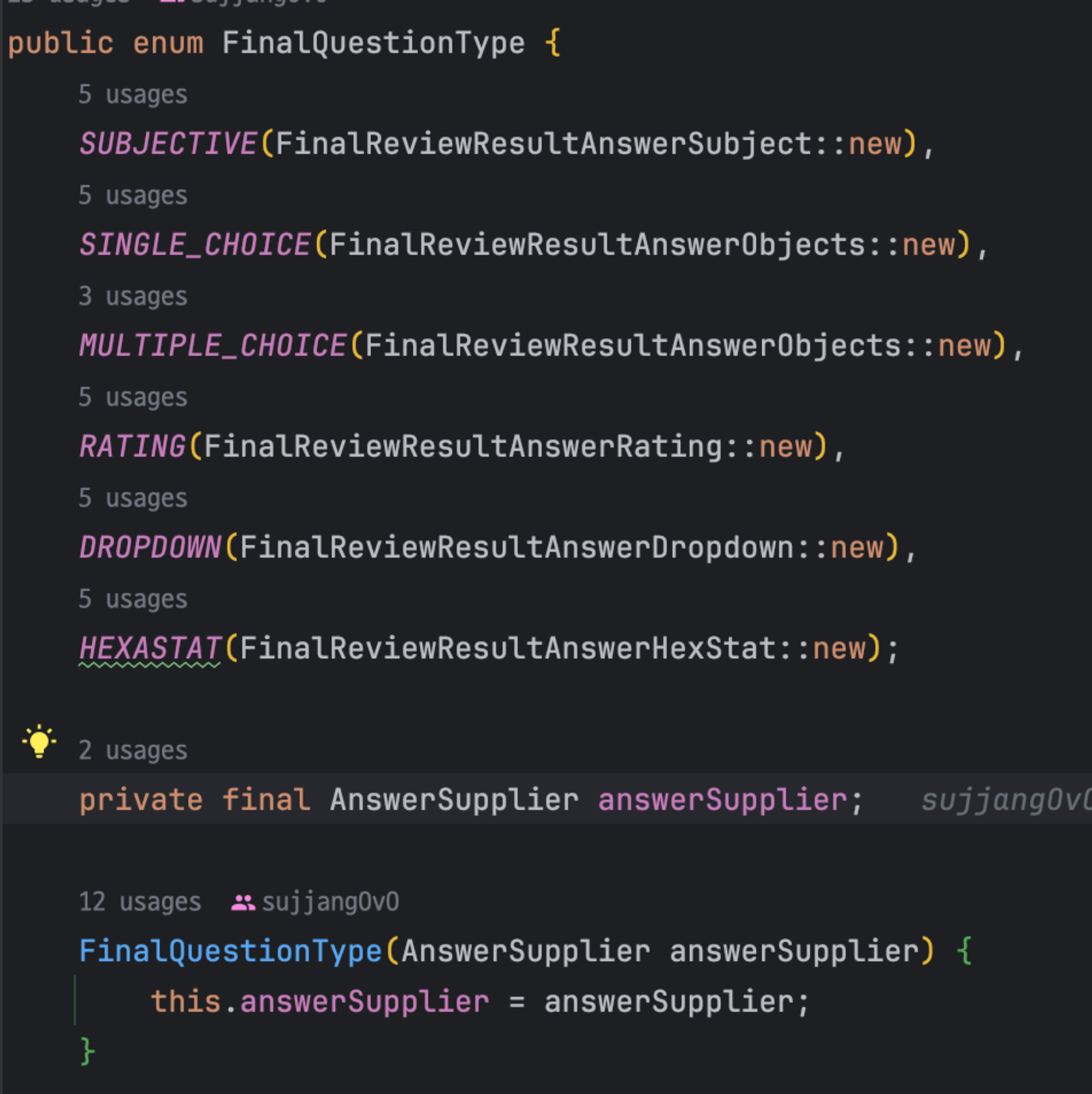
처음엔 각 type별 answer entity를 `answerSupplier`를 통해 반환할 수 있도록 enum class에서 구현하였다

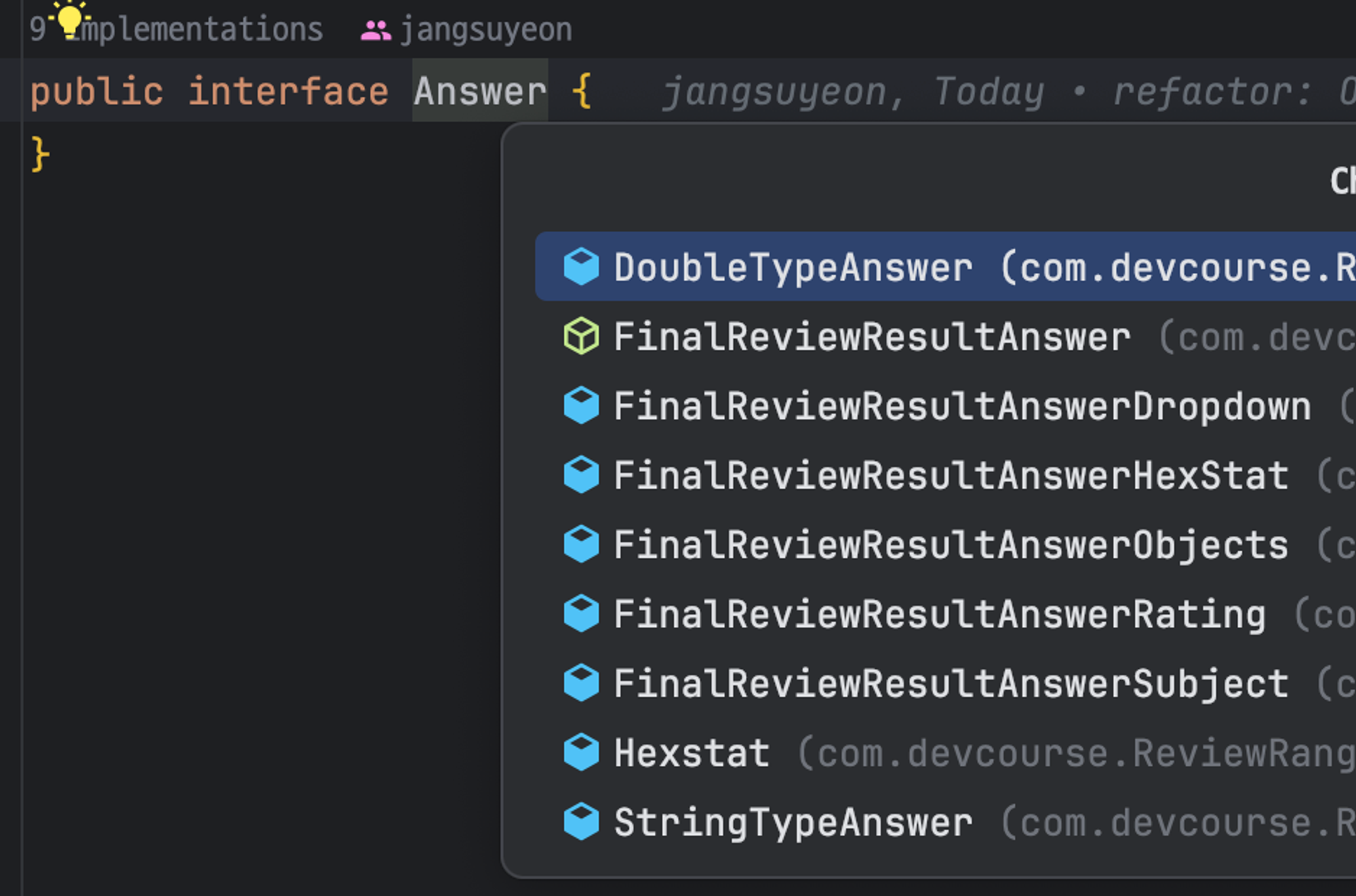
각 type별 answer entity는 Answer 인터페이스를 구현받고 있기 때문에 `answers` 리스트에 추가할 수 있다
여기까지는 아직 아래 분기문이 남아있는 상황이다. 각 타입별 repository에 대한 의존성이 필요하기 때문이다.
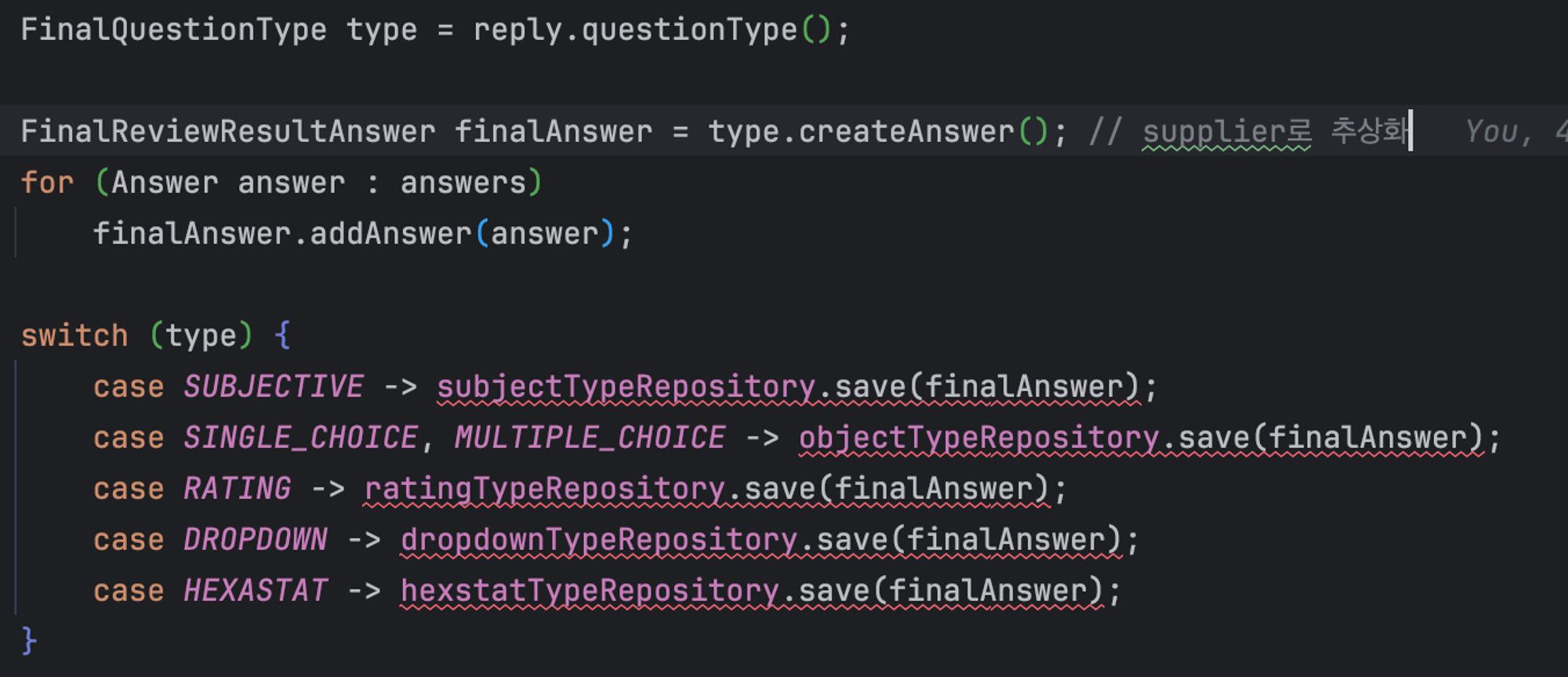
이후에 해당 분기문을 어떻게 없앨지 첫번째로 시도한 방안이다. (미리 말하지만 이 방법은 실패했다!)
이 방법은 `FinalQuestionType` enum class에 `AdapterSupplier`를 반환하는 방안으로 각 구현체 타입에 맞는 AdapterSupplier가 save를 수행하도록 했다
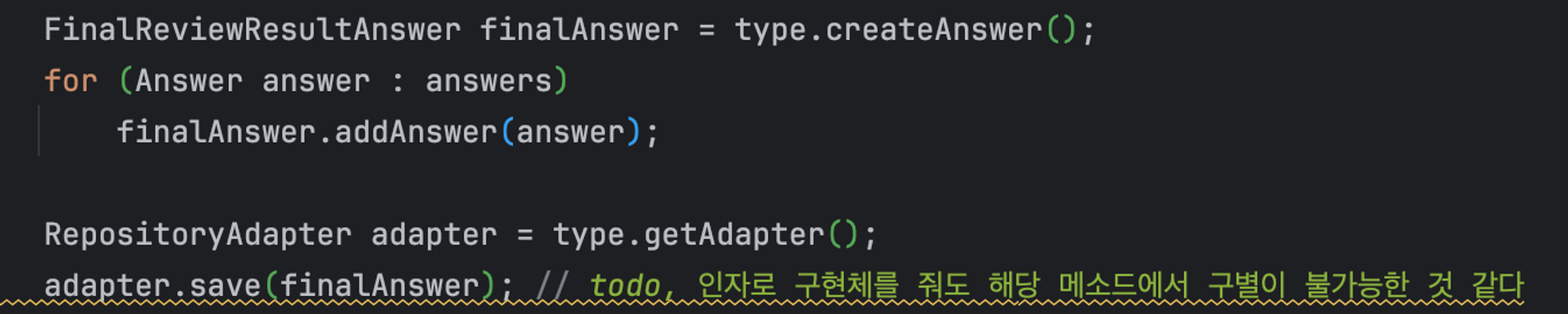
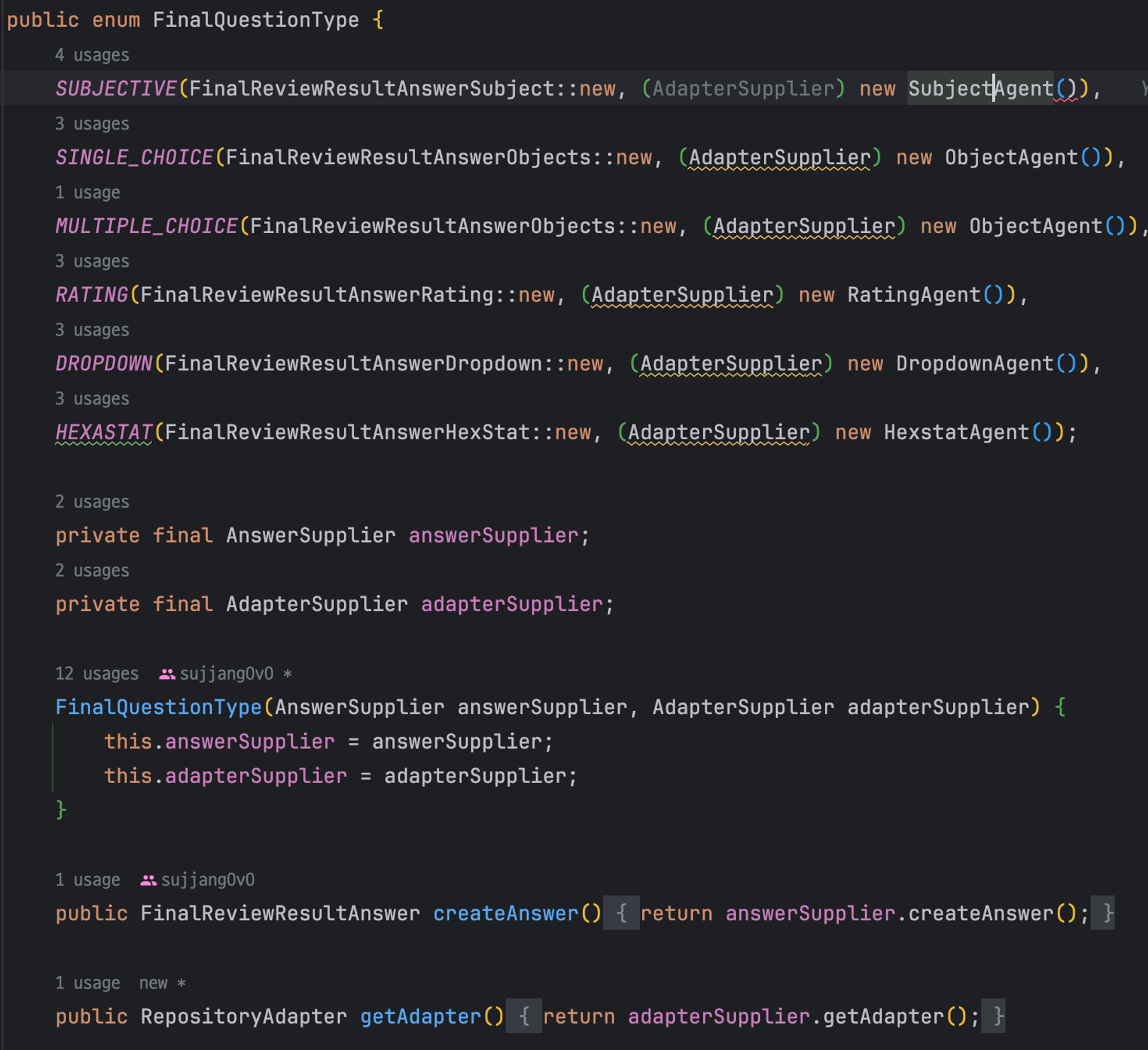
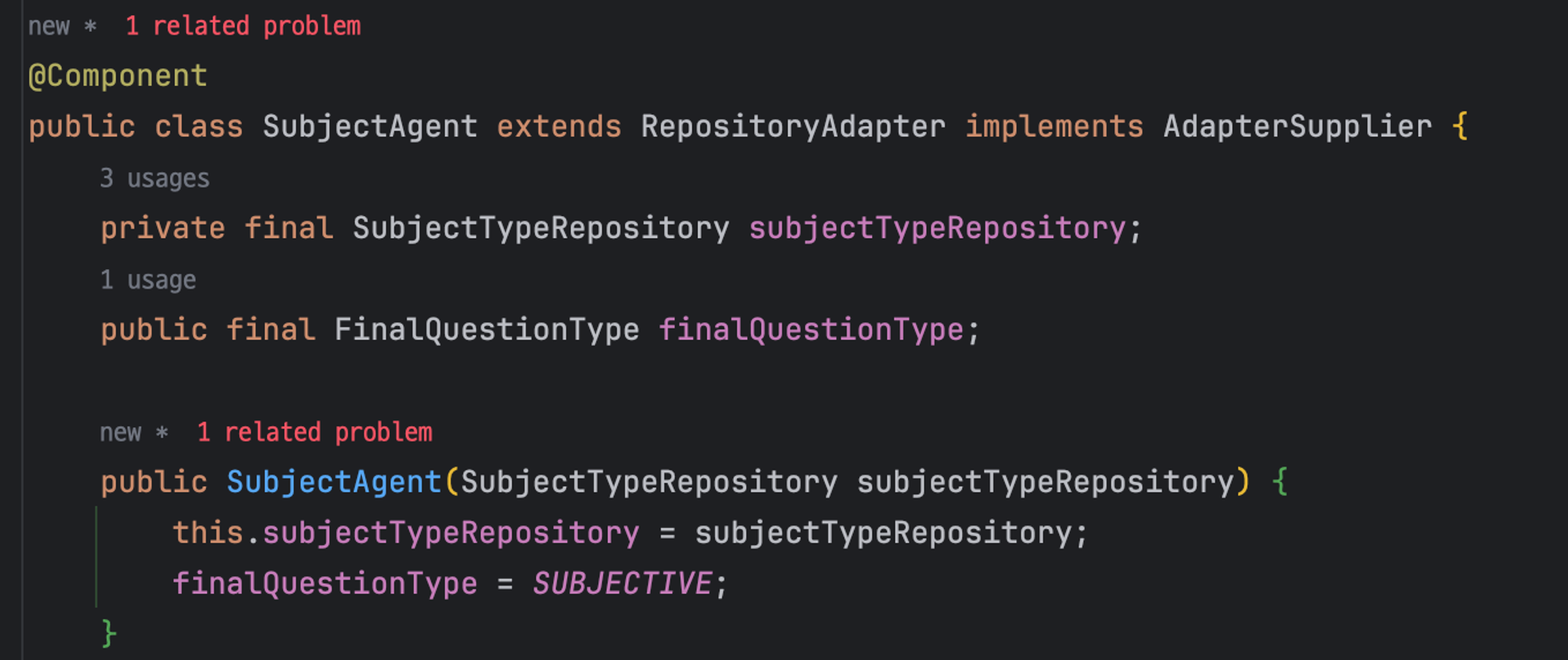
그러나 `type.apdater`로 repository를 받아서 Agent에 위임하는 방식은 Enum class에 너무 많은 역할을 부여한다는 생각이 들었다
Enum은 열거형 클래스로 ‘싱글톤’이 주된 목적이다.
그래서 해당 코드의 문제는 Subject에 이미 @Component가 붙어 bean등록이 되었는데 Enum에서 또 빈 등록(싱글톤) 만들고있어 충돌이 나고있다
두번째 방안으론 이를 “팩토리 메소드”로 해결하고자 했다 ⭐⭐⭐
Enum의 목적은 열거, 나열이다. 지금 내가 하고자 하는 것은 각 테이블에 맞는 repository에서 데이터를 save하는 것이므로 팩토리 메소드로 해결이 가능할 것이다.
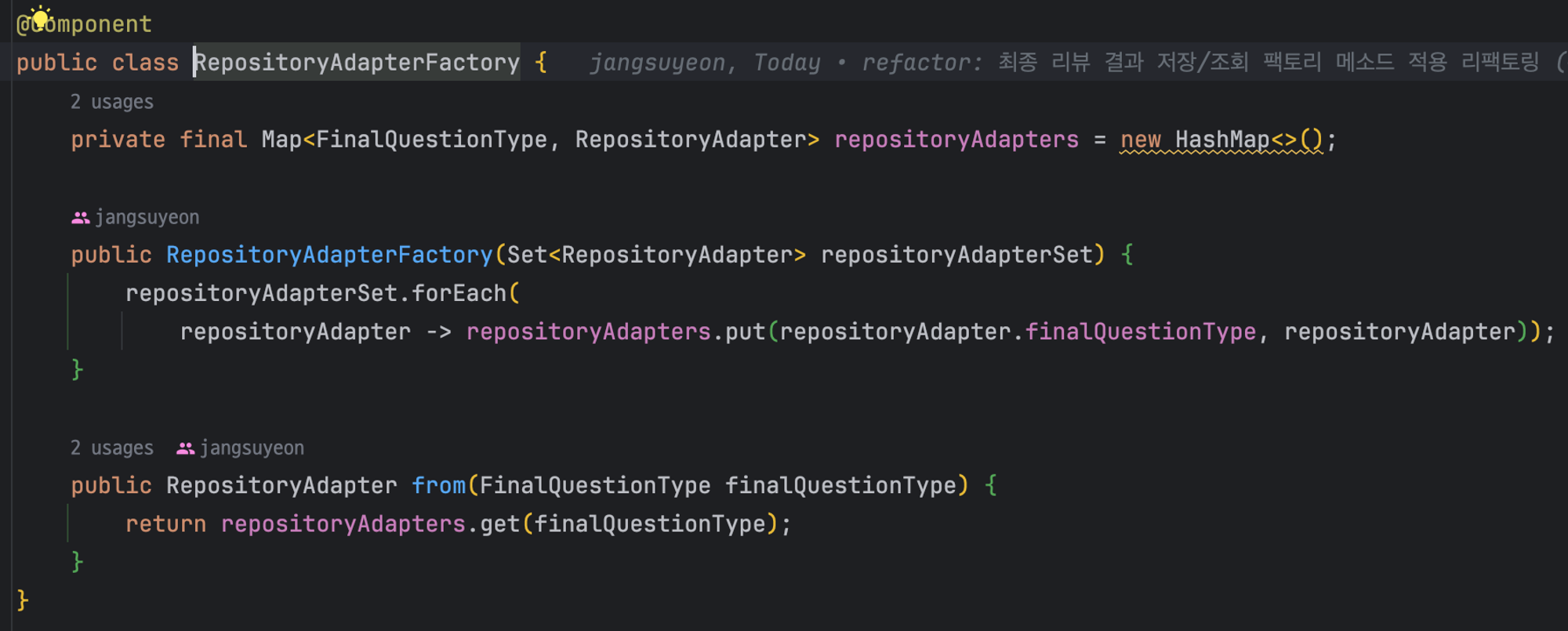
팩토리 클래스 또한 `@Component` 로 빈 등록이 되기 때문에 실행할 때 생성자를 통해 각 Adapter의 타입이 key
그리고 각 타입별 `RepositoryAdapter` 의존성이 `repositoryAdapters`에 주입될 것 이다.
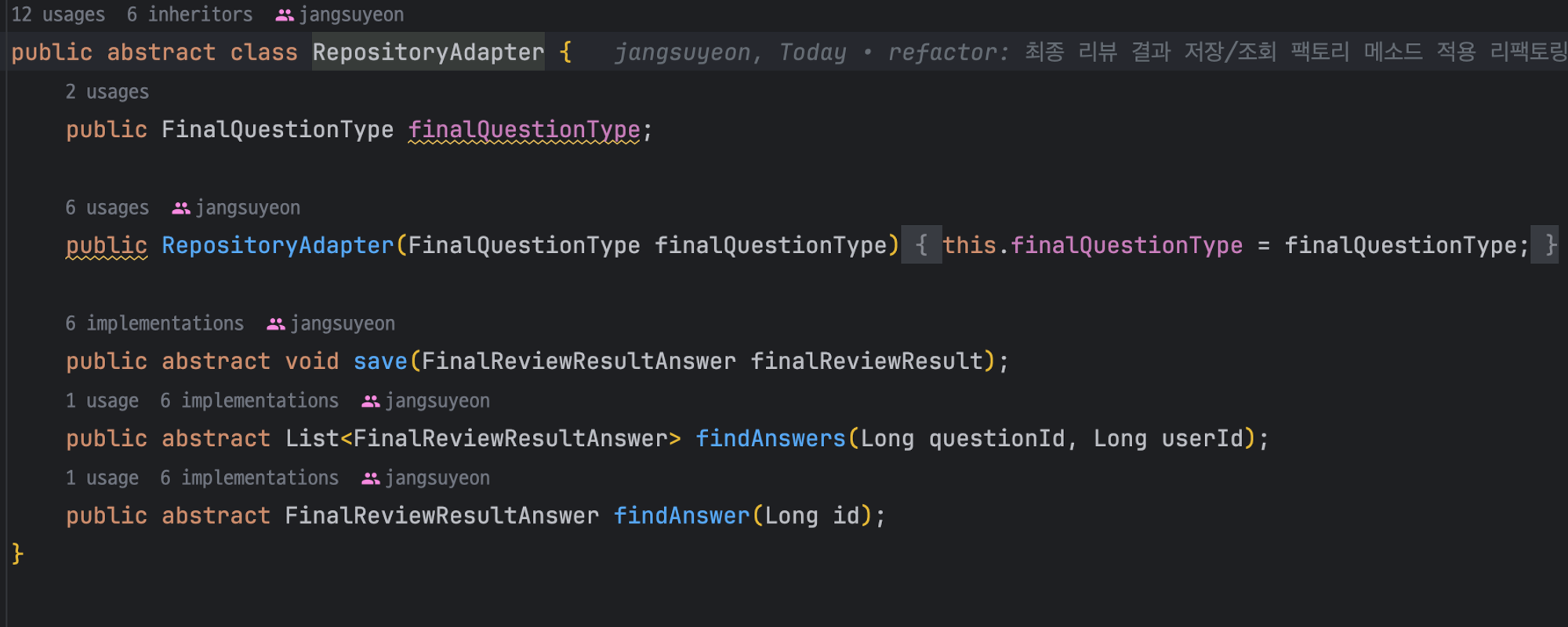
위는 추상 클래스 `RepositoryAdapter`의 구조이다.
`finalQuestionType`를 하위 클래스에서 무조건 필드로 갖도록 추상 클래스의 필드와 생성자로 지정해 주었다.
추상화한 각각의 메소드들의 역할은 아래와 같다
`save`- 각 타입별 repository에 데이터를 저장하도록 한다
`findAnswers` - 각 타입별 repository로부터 데이터 목록을 받아온다
`findAnswer` - 각 타입별 repository로부터 단일 데이터를 받아온다
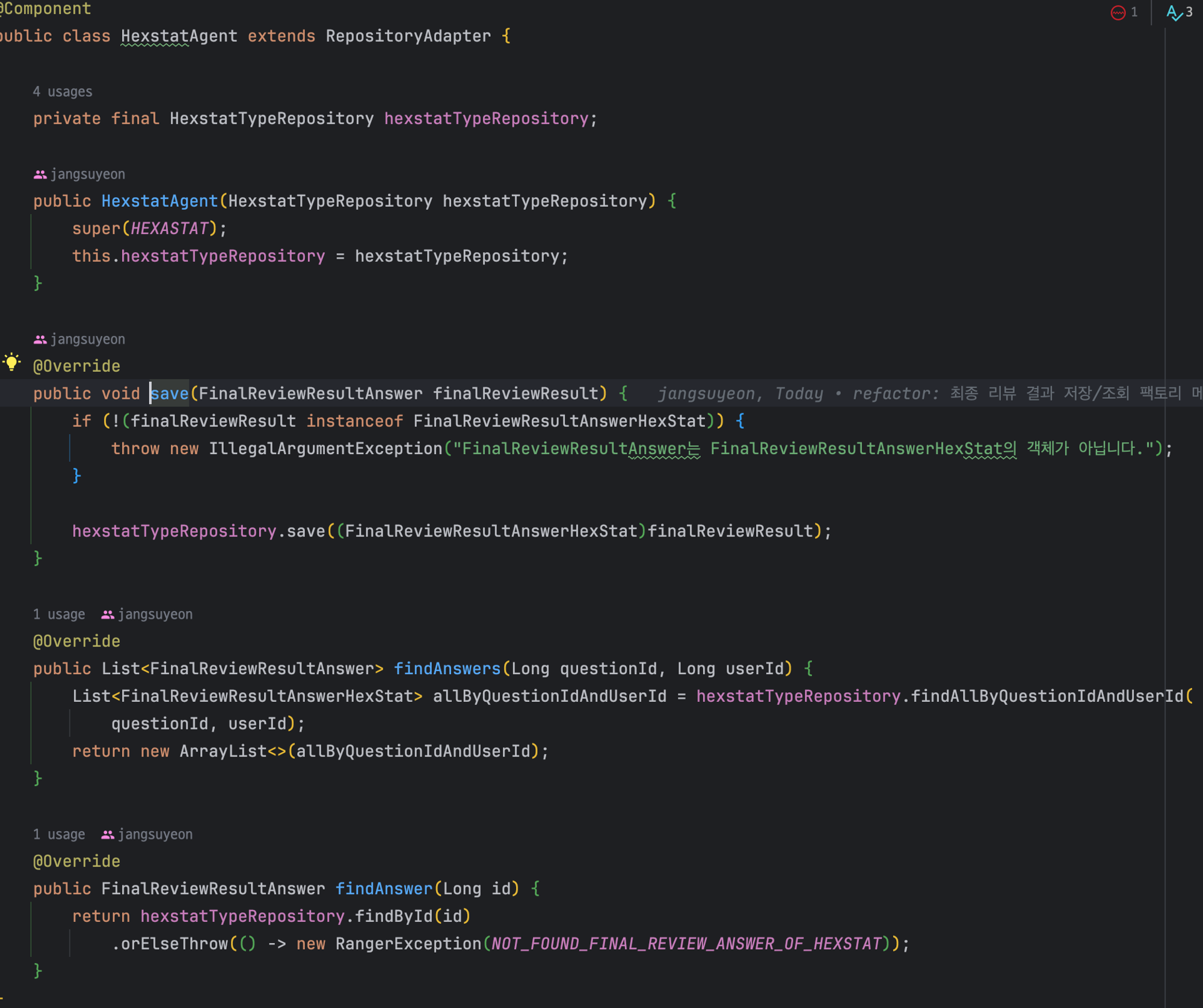
추상 클래스 `RepositoryAdapter`의 구현체 중 1개인 `HexstatAgent`를 알아보자.
상위 클래스의 상속을 통해 `finalQuestionType`을 설정하고 있다
그리고 생성자를 통해 각 `타입별 repository` 주입받았다.
각 타입에 맞는 repositry를 이용해 `save`, `findAnswers`, `findAnswer`을 수행하고 있는 모습이다.
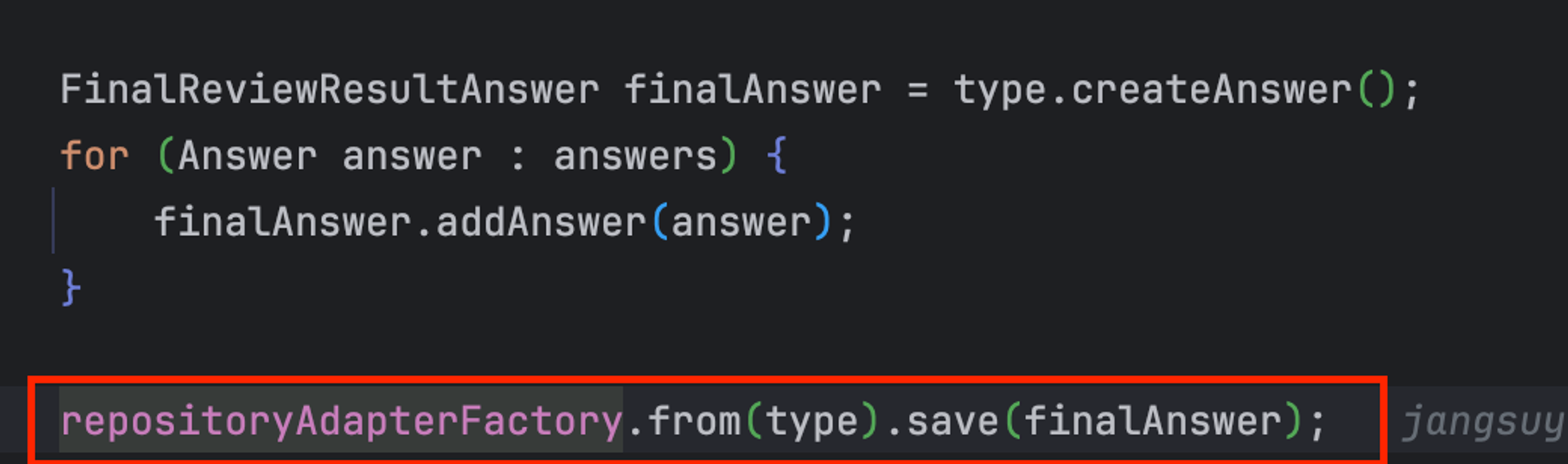
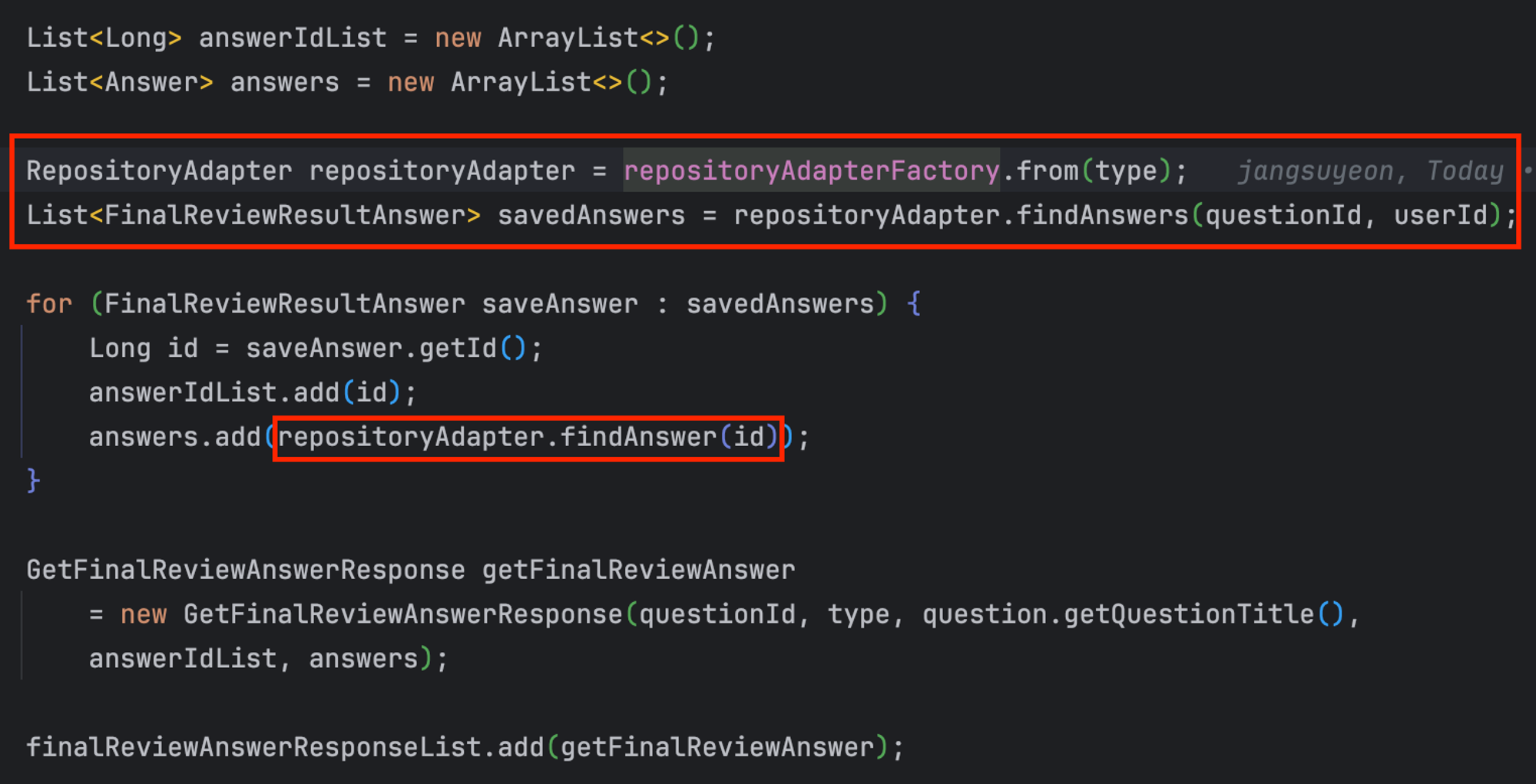
이러한 `RepositoryAdapter`, `Agent`, `RepositoryAdapterFactory`를 통해 추상화를 구현하였다.
또한, swtich문(분기문)을 없애고 단 한줄로 데이터를 DB에 저장할 수 있게 되었다!! (유지보수성 확장)
switch (finalQuestionType) {
case SUBJECTIVE -> {
FinalReviewResultAnswerSubject subjectAnswers
= subjectTypeRepository.findByQuestionIdAndUserId(questionId, userId)
.orElseThrow(() -> new RangerException(NOT_FOUND_FINAL_REVIEW_ANSWER_OF_SUBJECT));
answerIdList.add(subjectAnswers.getId());
answers.add(subjectAnswers.getSubjects());
}
case SINGLE_CHOICE, MULTIPLE_CHOICE -> {
List<FinalReviewResultAnswerObjects> objectAnswers
= objectTypeRepository.findAllByQuestionIdAndUserId(questionId, userId);
for (FinalReviewResultAnswerObjects answer : objectAnswers) {
answerIdList.add(answer.getId());
answers.add(answer.getObject());
}
}
case RATING -> {
List<FinalReviewResultAnswerRating> ratingAnswers
= ratingTypeRepository.findAllByQuestionIdAndUserId(questionId, userId);
for (FinalReviewResultAnswerRating answer : ratingAnswers) {
answerIdList.add(answer.getId());
answers.add(answer.getRate());
}
}
case DROPDOWN -> {
List<FinalReviewResultAnswerDropdown> dropdownAnswers
= dropdownTypeRepository.findAllByQuestionIdAndUserId(questionId, userId);
for (FinalReviewResultAnswerDropdown answer : dropdownAnswers) {
answerIdList.add(answer.getId());
answers.add(answer.getDrops());
}
}
case HEXASTAT -> {
List<FinalReviewResultAnswerHexStat> hexstatAnswers
= hexstatTypeRepository.findAllByQuestionIdAndUserId(questionId, userId);
for (FinalReviewResultAnswerHexStat answer : hexstatAnswers) {
answerIdList.add(answer.getId());
String statName = answer.getStatName();
Double statScore = answer.getStatScore();
Hexstat hexstat = new Hexstat(statName, statScore);
answers.add(hexstat);
}
}before
after
마찬가지로 Adapter를 통해 findAnswer, findAnswers를 구현하여 `getFinalReviewAnswerList` 조회 메소드의 분기문도 삭제할 수 있었다.
이전에는(before 코드) 각 타입별 repository를 통해 읽어오고 데이터를 추가하는 과정이 이루어 졌지만 after에선 adapter를 통해 각 타입별 구현체가 repository의 find를 호출한다
상위 인터페이스인 FinalReviewResultAnswer으로 받아오기 때문에 데이터를 추가하는 과정에도 문제가 없음을 확인할 수 있다.
참고로 현재는 설계상 Type별로 Repository가 있어 Table이 따로있다.
이렇게 되면 쿼리를 여러번 날려야 하는 비효율성이 발생하게 된다. => 설계상의 문제, 유지보수 어려움
그래서 추후 JSON 타입으로 RDBMS에 저장하던지 or MongoDB와 같은 NoSQL을 사용해서 하나의 테이블에서 여러개의 데이터를 관리하도록 고도화 된 리팩토링을 진행하자.
이렇게 한 테이블에 데이터가 있으면 1개의 쿼리로도 데이터를 조회할 수 있게되어 효율성이 좋아진다.
또한, 타입이 추가되어도 테이블이 증가되지 않아 유지보수에도 좋은 점이 있다는 것을 알아두자.
4️⃣ `orElseGet` 과 같은 가독성이 떨어지는 구문을 수정하자

orElseGet은 성공인지, 실패인지 따라가기가 어렵다는 문제가 있다
따라서, 성공했을 때만 아래의 코드가 성공적으로 수행할 수 있도록 하고 성공하지 못한다면 예외를 발생시키자
5️⃣ 너무 많은 기능을 가진 crate 메소드를 메소드 분리를 통해 가독성을 높이자
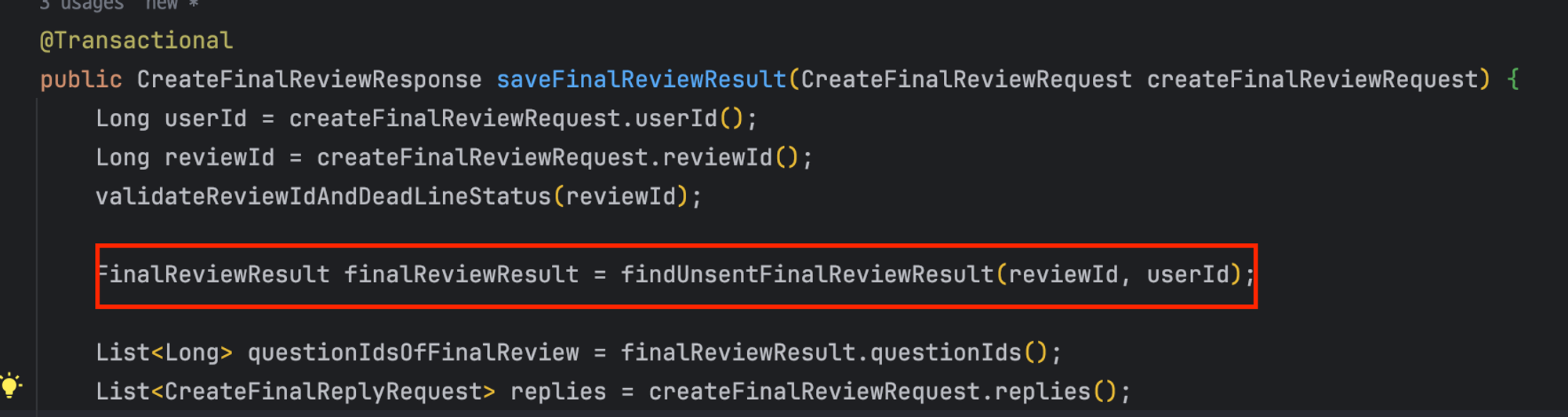

‘전송 안 된’ 최종 리뷰 결과를 찾는 것도 로직의 일원이다
따라서, 저장 및 전송 메소드에 있는 해당 로직(=전송 안된 최종 리뷰 찾기)에 대한 메소드 분리를 진행하였다
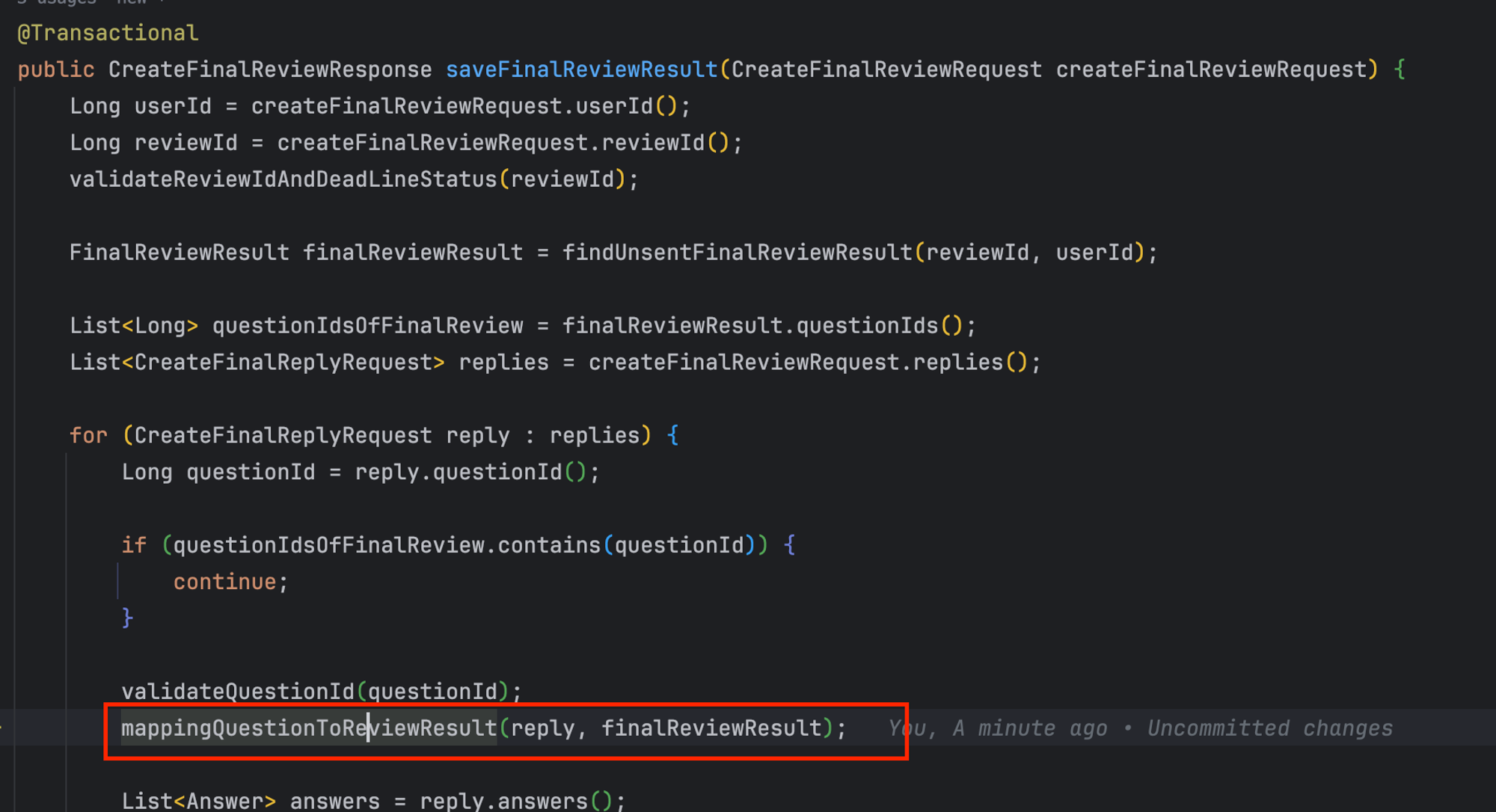

‘최종 질문’을 최종 리뷰 결과에 등록하는 과정 또한 별도의 로직이다
따라서 저장 메소드에 있는 해당 로직(=최종 질문을 최종 리뷰 결과에 등록)에 대해 메소드 분리를 진행하였다
리팩토링 후기
처음 개발을 시작할 땐 프로젝트 기간을 엄수하기 위해 기간내 구현에 초점을 두었다
구현을 하면서도 이 부분은 더 좋아질 수 있을 것 같은데? 라는 생각도 들었었고 왜 이 부분은 이렇게 복잡하게 로직이 진행되지? 라는 생각도 들었었다
추후 개발이 끝난 후 해당 리팩토링을 통해 분기문 로직은 충분히 추상화를 통해 리팩토링 할 수 있는 부분이었고 로직이 복잡한 부분은 초반 도메인 설계가 잘 못 이루어졌단 점을 깨달았다
이번 분기문 리팩토링 경험을 통해 자바의 꽃인 추상화의 중요성과 도메인 설계에 대한 중요성을 한 번 더 상기하게 되었다