해당 게시글은 "프로그래머스 데브코스 4기"의 팀 내 프로젝트 기록용으로 TECH BLOG에 직접 작성한 글입니다.
🩶 N+1 문제란?
최대한 연관관계가 없이 Long타입으로 id만 받아서 프로젝트를 진행하던 와중..!
결국 review와 product, user의 연관 관계가 필요한 상황이 발생하게 되었다.


그래서 N:1 연관 관계를 맺었는데..! 연관 관계를 맺는 동시에 N+1문제가 발생하였다
N+1문제란, 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것이다.
원치않는 쿼리가 실행된다면 시스템의 성능이 저하될 수 있다.
Q. Lazy(지연로딩)옵션을 걸어줘서 괜찮은 거 아닌가요?
A. 하위 엔티티로 작업을 하게 되면 추가적인 조회가 어차피 발생하기 때문에 결국 N+1문제가 발생하게 된다.
물론! EAGER(즉시로딩)인 경우 하위엔티티로 작업하지 않아도 해당 데이터의 연관 관계로 맺어진 하위 엔티티들을 추가적으로 조회하기 때문에 N+1문제가 발생한다.
✅ 차이는 하위엔티티로 작업하냐 안하냐지만 결국 하위엔티티를 사용하게 된다면 어떤 로딩이든 N+1문제가 발생하는 것이다.
❔ 어떻게 해결할 수 있나요?
크게 2가지 해결 방법이 있다.
- Fetch Join
- Entity Graph
해당 프로젝트에서는 N+1문제를 해결하기 위해 1번의 Fetch Join을 채택하여 이에 대해 다루어 보도록 하겠다.
굳이 2번이 아닌 1번을 선택한 이유로는 Entity Grapth는 Outer Join을 기본으로 하며 Fetch Join은 Inner Join을 기본으로 한다.
성능상 Inner Join이 더 유리하기도 하고 사용하기에도 1번이 더 용이하므로 1번을 사용하는 것이다!
🩶 Fetch Join이란?
Fetch Join이란 미리 두 테이블을 JOIN하여 한 번에 모든 데이터를 가져올 수 있도록 하는 방법이다.
N+1 문제가 발생하는 원인인 “한쪽 테이블만 조회 후 연결된 다른 테이블은 따로 조회”를 해결하기 위함이다.
미리 두 테이블을 JOIN해두고 모든 데이터를 가져온다면 N+1문제가 발생하지 않기 때문이다.
Fetch Join은 두 테이블을 JOIN하는 쿼리를 직접 작성해야 하는데 이를 위해 JPQL을 사용한다.
간단하게 JPQL(Java Persistence Query Language)에 대해 설명하자면 엔티티 객체를 조회하는 객체지향 쿼리이다.
즉, 테이블을 대상으로 작성하는 쿼리가 아니라 “엔티티 객체”를 대상으로 하는 쿼리인 것이다!
SQL과 비슷한 문법을 가지지만 차이가 존재하고 JPQL은 결국 JPA에 의해 SQL로 변환된다!!
가장 큰 차이로는 대소문자 구분, from절은 테이블이 아닌 엔티티로, 별칭 필수 명시정도가 있다.
JPQL에 대해서는 이정도로 간단하게 넘어가고 Fetch Join을 사용하기 위해선 @Query 을 사용하여 쿼리를 직접 작성하면 된다.
이때 주의할 점은 fetch join이 아니라 문법 상 join fetch로 작성해야 함을 유의해야 한다
@Query("SELECT DISTINCT o FROM Owner AS o ***JOIN FETCH*** o.pets")
List<Owner> findAllJoinFetch();✅ 해당 쿼리 결과론 쿼리가 1번만 발생하고 Owner와 pet 데이터를 Inner Join해서 가져오게 된다.
물론 Fetch Join도 단점이 존재한다.
- 쿼리 한번에 모든 데이터를 가져오기 때문에 JPA가 제공하는 Paging API 사용 불가능
- Pageble 사용 불가
- 1:N 관계가 두 개 이상인 경우 사용 불가능
- 패치 조인 대상에게 별칭 부여 불가능
- 쿼리문 작성을 직접 해야 한다는 단점
하지만 쿼리가 여러번 나가지 않고 1번만 나간다는 점이 성능상에서 큰 이점이라 사용하게 되는 것 같다.
Fetch Join VS Outer Join
Fetch Join은 연관 관계가 있는 것만 Join한다. SQL에는 존재하지 않는 문법이고 JPA에만 존재한다.
반대로, Outer Join은 연관 관계가 없는 것 까지 전부 Join하는 카테시안 곱을 수행하게 된다.
✅ 카테시안 곱을 수행하느냐 연관 관계가 있는 것만 수행하느냐의 차이가 가장 크다!
물론 Fetch Join에도 카테시안 곱(Cartesian)이 발생하여 중복이 생길 수 있다.
이를 방지하기 위해 JPQL에 DISTINCT를 추가하여 중복을 제거하거나 OneToMany 필드 타입을 Set으로 선언하여 중복을 제거할 수 있다.
* 카테시안 곱: join 조건에 on이 없을 때 모든 데이터를 전부 결합하여 테이블에 존재하는 행 갯수를 곱한만큼 결과값을 반환하는 것
🩶 사용법


상품은 여러 개의 리뷰를 가질 수 있으며 사용자는 여러 개의 리뷰를 작성 할 수 있어 위와 같은 연관 관계가 맺어진다.
그래서 n쪽인 Review가 ManyToOne으로 연관 관계의 주인을 담당하고 있다.
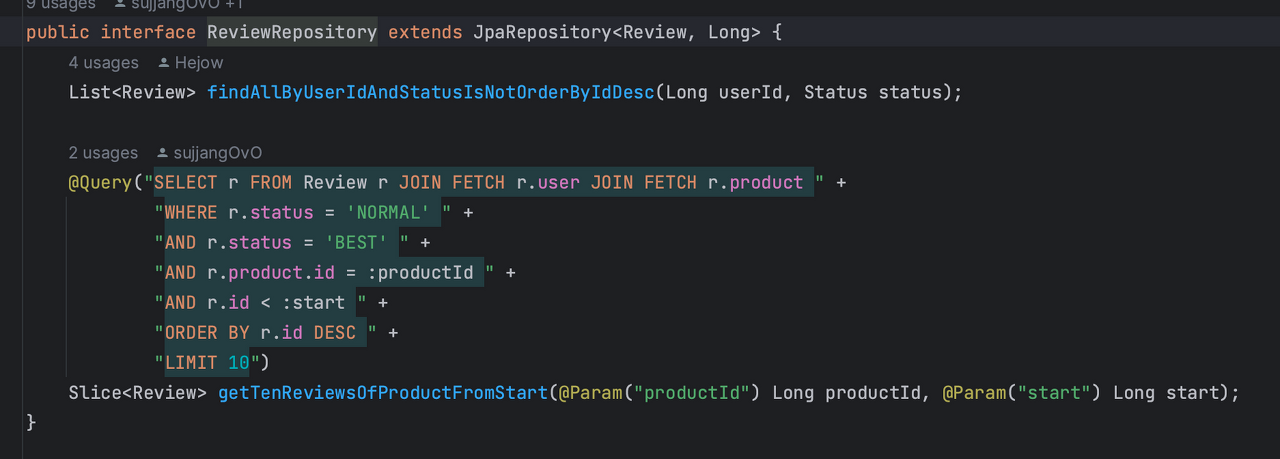
@Query("SELECT r FROM Review r JOIN FETCH r.user JOIN FETCH r.product " +
"WHERE r.status = 'NORMAL' " +
"AND r.status = 'BEST' " +
"AND r.product.id = :productId " +
"AND r.id < :start " +
"ORDER BY r.id DESC " +
"LIMIT 10")JPQL을 이용해 Fetch Join을 Repository에 정의해 주었다.
JPQL 문법에 따라 파라미터를 받기 위해 콜론(:)을 이용해 데이터가 추가될 곳을 지정해 주었다.
즉, BANNED, DELETED되지 않은 리뷰중에서 해당 상품의 아이디와 같은 리뷰를 찾아서 현재 페이지보다 작은 곳부터 최신순으로 10개의 데이터를 가져오는 쿼리가 완성된 것이다.
코드확인: 관련 PR (#44)
Reference
'Development Tools > jpa' 카테고리의 다른 글
| [JPA] deleteAll과 deleteAllInBatch의 차이 (2) | 2023.10.19 |
|---|---|
| [JPA] JPA가 기본 생성자가 필요한 이유 (feat. final) (0) | 2023.10.12 |
| [JPA] CASCADE.ALL로 인한 버그 발생 및 해결법 (0) | 2023.09.25 |
| [jpa] hibernate 자동 생성되는 sql 확인하기 (0) | 2023.09.04 |


